Zscalerのブログ
Zscalerの最新ブログ情報を受信
スキャナーが考え始めるとき:セキュリティ テストにおけるMythosとGPT 5.5 Cyberからの教訓

概要
Anthropic MythosやOpenAI GPT 5.5 Cyberといった最先端AIモデルは、組織のセキュリティにとって重要な転換点をもたらしています。これらはAIをワークフローに組み込もうとするセキュリティ エンジニアにとって革新的な可能性を切り開く一方で、脅威アクターによって悪用された場合、ますます高度化する攻撃に直面する組織の攻撃対象領域を拡大させる側面もあります。MythosとGPT 5.5 Cyberは、従来のモデルとは根本的に異なることを行います。これらは攻撃経路全体を踏まえて推論を行い、悪用可能性を評価しながら、セキュリティ関連のワークフローを生成します。脅威チェーンは変わっていません。攻撃者は今後も、露出している部分を探し出し、弱点を突いて侵入し、水平移動してデータを盗み出すでしょう。変化したのは、必要とされる専門知識、スピード、規模です。
問題は、これらのモデルがセキュリティ態勢に影響を与えるかどうかではなく、担当部門が攻撃者よりも早くそれらを活用できるかどうかです。このブログでは、Zscalerでこれらのモデルをテストして得られた知見を共有します。つまり、セキュリティ運用や脆弱性管理にどのようなメリットをもたらすか、そして組織のサイバー防御にとってどのような意味を持つかについて紹介します。
最先端モデルのテスト手法
セキュリティ テストにおける最先端AIの潜在能力を最大限に引き出すため、私たちは3つの主要なテスト ハーネスを中心とした専用の評価フレームワークを開発しました。それぞれのテスト ハーネスは、現実世界の攻撃と防御のシナリオを反映するように設計されています。
- 攻撃者のような思考 - ブラック ボックス テスト:このモデルは、内部システムに関する知識を一切持たずにターゲットにアプローチし、意図をもった外部攻撃者の視点をシミュレートします。このテストによって検証された結果は、実際に悪意のある攻撃者が悪用する可能性が高いため、直ちに是正措置の対象となります。
- 防御側による最初の評価 - アーティファクトとコード リポジトリーのテスト:このモデルは、ソース コード、コンパイル済みバイナリー、静的ファイルを詳細に検査し、悪用される前にセキュリティ上の脆弱性を検出します。このツールは、他のツールに比べて確認された脆弱性の検出数は少なかったものの、複雑なシステムを分解・分析し、下流の動的検証に向けた高品質な脆弱性を検出するうえで非常に効果的であることがわかりました。
- 情報に基づく攻撃者 - グレー ボックス テストとホワイト ボックス テスト:このモデルは、脅威モデル、アーキテクチャー仕様、過去のスキャン結果など、システム コンテキストの一部または全部を武器に、豊富な情報を活用した高精度な分析を実行します。このアプローチにより、最も実用的な知見が得られ、モデルが侵害経路をより効果的に特定できるようになりました。ただし、その結果は、提供されるコンテキストの質と範囲に大きく左右されました。
このフレームワークを導入したことで、ようやく重要なものを測定できるようになりました。AIが単にセキュリティ上の問題を見つけられるかどうかではなく、最先端AIがこれまでのどの手法よりも速く適切な問題を見つけられるかどうかが重要なのです。
すべての実行は、攻撃対象領域のマッピング、テスト計画、アクティブ テスト、動的検証、重複排除、トリアージ、チケット発行、パッチ適用、検証という共通のパイプラインに沿って進められました。この構成は、動的検証で維持された内容、重複排除後の深刻度の変化、修復までの経路の明確さといったコンテキストを考慮し、綿密に設計されています。
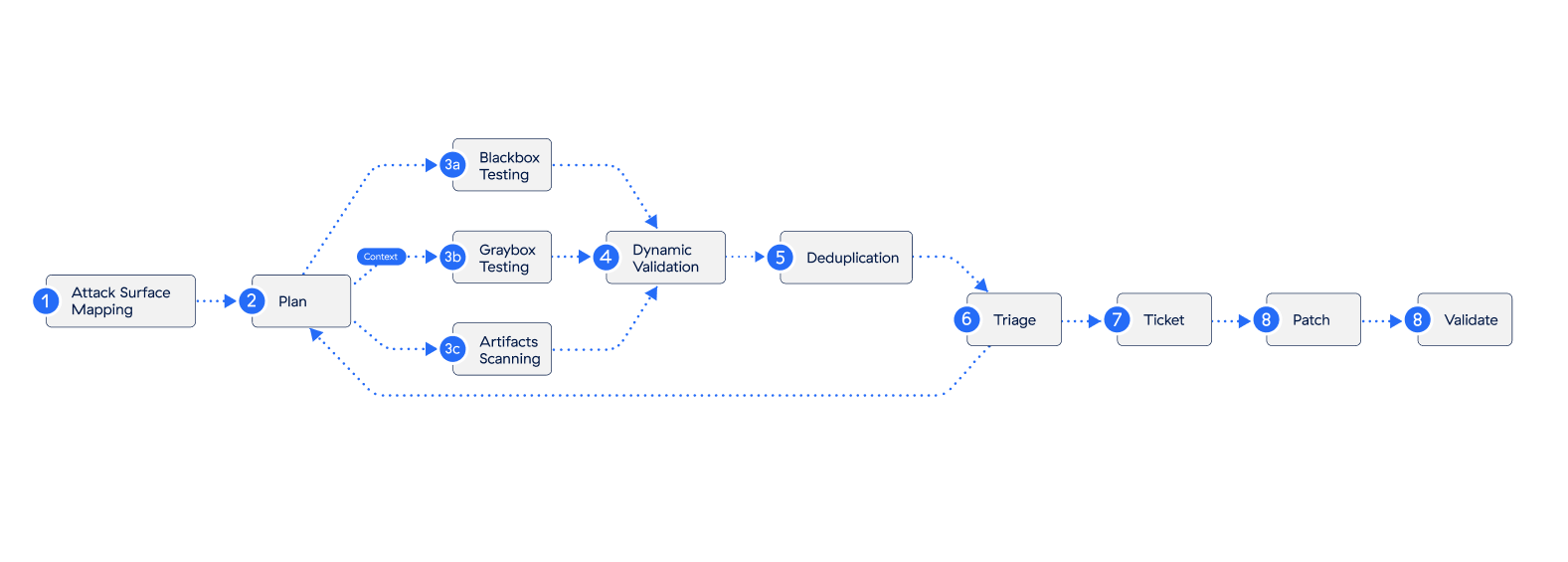
図1:新しい最先端AIモデルの能力を評価するために使用した3つの主要なテスト ハーネス。
MythosとGPT 5.5サイバー モデルの仕組み:セキュリティ推論における根本的な変化
新たな最先端AIモデルを従来のセキュリティ ツールと区別する決定的な機能は、多段階推論です。これらのモデルは、個々の発見を返すのではなく、完全な攻撃経路を構築します。つまり、前提条件、権限状態、設定ミス、下流の脆弱性を連鎖的に結びつけ、実際の攻撃者の活動を模倣するのです。
私たちはセキュリティ機能のあらゆる側面においてこれらのモデルを徹底的に検証しました。その調査結果は以下のとおりです。
機能 | セキュリティ部門にとっての価値 |
攻撃経路分析 | 個々の弱点がどのように組み合わさって、実行可能な侵害経路となり得るかを特定します。 |
実証可能な悪用 | 検証結果を、実際に動作する概念実証エクスプロイト スクリプトで裏付け、結果を独自に検証する。 |
脆弱性の優先順位付け | 理論上のリスクと、実際に発生し悪用可能なリスクを区別することで、担当部門が重要なことに集中できるようにする。 |
反復分析 | パターンに基づいた一回限りの回答を返すのではなく、問題全体にわたって段階の推論を動的に行うことができる。 |
検出エンジニアリング | 検出、脅威ハンティング、分析ロジックの作成と改良を加速させる。 |
調査サポート | インシデント発生時の証拠収集、要約、データ分析を迅速に支援する。 |
修復ガイダンス | 想定される攻撃者の行動に合わせた対策と是正措置を推奨する。 |
運用速度 | 特に複雑な環境において、シグナルの検出から意思決定までの時間を短縮する。 |
私たちが評価したすべての機能のなかで、攻撃チェーンと反復分析が最も重要でした。最先端モデルは単に脆弱性を列挙するだけでなく、それらを横断的に推論を行い、権限状態、設定ミス、情報漏洩を関連付けて、現実的な多段階攻撃経路へと結びつけます。
以下は、このモデルの高度な推論能力を示す例です。
マルチパス攻撃チェーン:複数の角度から同じ目標に集中
MythosとGPT 5.5 Cyberは、これまで以上に推論能力を拡張し、同一の攻撃目標に対する複数の同時攻撃経路を探索できます。初期のエンドポイント マッピングから開始し、モデルは独立した脆弱性チェーンに分岐し、脆弱性と設定ミスを組み合わせ、中間的な攻撃者の状態(認証情報、トークン、セッション データ)を保持したまま、単一の大きな影響をもたらす結果に収束します。

図2: 3つの独立した経路。1つに収束する結果。完全な推論チェーンを維持したまま、自律的に特定。
最先端モデルはセンサー性能がより優れています。これらは多くのノイズを除去しながら、より微弱なシグナルを検出し、高速に実行します。データ自体は常に存在していましたが、変化したのはそれを完全かつ実用的な全体像に落とし込む能力です。この規模で人間がそれを行うことは困難であり、場合によっては不可能です。
MythosとGPT 5.5 Cyberのテストから得られた重要な教訓
今回のベンチマーク テスト全体を通して、最先端モデルは従来のツールやペネトレーション テスト手法と比較して、2倍の速度で、2倍多くの高重大度の検出結果を提示しました。しかし、より重要なのは検証に耐えた結果です。最終的に有効とされた結果はすべて正確な重大度評価、明確な再現手順、現実的な攻撃者の行動に基づいた修復ガイダンスを備えており、実行可能なものでした。
これは、従来のツールと比較してシグナル対ノイズ比が大幅に改善され、実用的な結果が得られたことを意味します。
重要な学び
- 差別化要因は、スキャン速度だけでなく推論の深さ:最先端モデルは、より速くスキャンする点ではなく、より深く考える点で優れています。つまり、従来のツールでは完全に見逃されていた、個別では低重大度に見える検出結果同士を結びつけ、重大な攻撃経路へと連鎖させます。
- コンテキストは諸刃の剣:アーキテクチャーのコンテキスト、脅威モデル、既知の脆弱性を提供することで、精度は大幅に向上しました。しかし、直感に反するリスクも存在します。モデルに過去に発見された問題クラスの例を入力すると、それらのパターンに固執し、まだ発見されていない問題の探索を停止してしまったのです。モデルには環境に関する情報を与えるべきですが、結論に誘導してはなりません。
- コンテキストがないと重大度は過大評価される:十分な前提情報がない場合、モデルは依存関係を誤って解釈し、結果を過剰に誇張してしまいます。コンテキストを考慮した推論が、有意義な結果を得るための最低限の条件です。
- 専門家主導の集中的なワークフローは広範な使用よりも優れた成果を上げる:目的を絞らないプロンプトは、処理能力を無駄にし、ノイズを生み出します。関連するコンテキストを用いて、モデルを特定の目的(脆弱性の検出、コード スキャン、標的分析)に向けましょう。専門家主導の的を絞ったワークフローこそが、シグナルと雑多なノイズを区別する鍵となります。
- テスト ハーネスこそが力の増幅要因:モデルの品質は当然の前提条件ですが、真の力の増幅要因は、最先端AIを構造化された再現可能なテスト ハーネスに組み込むことです。Zscalerの最も効果的なワークフローは、製品セキュリティ部門が開発したコア セットを基に、エンジニアリング部門全体のセキュリティ チャンピオンによって改良されたものです。
セキュリティ リーダーが備える方法
最先端AIの能力は急速に普及しています。今後の課題はもはやモデルへのアクセスではなく、攻撃者がそれを攻撃に悪用する前に防御側がどのようににモデルを活用するかということになるでしょう。防御側は、この避けられない岐路に今から備えなければなりません。
Zscalerは、積極的な脆弱性管理にとどまらず、今すぐリスクを軽減するための影響力の大きい推奨事項を以下のとおり策定しました。
- アプリの不可視化:Zscaler Private Accessのようなゼロトラスト アーキテクチャーの背後にアプリケーションを移行することで、外部への露出リスクを軽減できます。攻撃者は到達できないものを侵害することはできません。
- 資産と関連リスクの把握:AI資産を含む、外部に公開されている資産と内部資産を完全に可視化します。この領域において、ZscalerはAI Asset Management、Asset Exposure Management、External Attack Surface Management、Unified Vulnerability Managementによって支援できます。
- デセプションによるプロアクティブな防御展開を優先:AIは目的達成段階に到達するために複数の経路を利用し、その過程で環境内に巧妙に配置されたデコイを誤って作動させます。Zscalerのお客様は、組み込み型のデセプション テクノロジーを展開することで、対象の資産やIDによる実際のアプリケーションへのアクセスを自動的に封じ込めると同時に、デコイ環境内での全活動を記録できます。
- あらゆる場所でゼロトラスト アーキテクチャーのを優先:リモート環境とオンプレミス環境の両方で、ゼロトラストを一貫して適用します。ユーザーとアプリケーション間のセグメンテーションを施行することで、水平方向への攻撃の拡散を防ぎ、AIによる攻撃の影響範囲を縮小します。
- 本番モデルに対するAIによるレッド チーム演習とガードレール:本番環境のAIを実際の攻撃対象領域のように扱います。プロンプト インジェクション、有害コンテンツ、ハルシネーション、時間の経過によるモデルのドリフトから保護します。
- AIを活用したエクスポージャー管理:リスクの高い領域についてはZscaler Exposure Management Remediation Agentを活用し、修復とパッチ適用を優先します(外部と内部両方の資産に適用可能です)。
まとめ
AIは、単純なアシスタントから、ミッションクリティカルな運用能力へと進化しつつあります。それは機会と緊急性の両方を生み出します。防衛側は、これまで人間の努力だけでは達成が困難だった方法で、スピード、精度、拡張性を向上させる機会を得ました。同時に、攻撃側も同様の同じ優位性を追求していくでしょう。
次の段階で主導権を握る組織は、最先端AIを強固なアーキテクチャー、信頼できるコンテキスト、規律ある運用と組み合わせた組織です。
Zscalerでは、最先端サイバー モデルとゼロトラストがまさにこの地点で自然に融合すると考えています。サイバー防御の未来は、アラートやダッシュボードの増加によって決まるものではありません。露出状況を理解し、攻撃経路全体を推論し、防御側が攻撃者よりも迅速かつ正確に行動できるよう支援するシステムによって定義されるようになります。これこそが、セキュリティ部門が今から備えるべき未来です。

免責事項:このブログは、Zscalerが情報提供のみを目的として作成したものであり、「現状のまま」提供されています。記載された内容の正確性、完全性、信頼性については一切保証されません。Zscalerは、ブログ内の情報の誤りや欠如、またはその情報に基づいて行われるいかなる行為に関して一切の責任を負いません。また、ブログ内でリンクされているサードパーティーのWebサイトおよびリソースは、利便性のみを目的として提供されており、その内容や運用についても一切の責任を負いません。すべての内容は予告なく変更される場合があります。このブログにアクセスすることで、これらの条件に同意し、情報の確認および使用は自己責任で行うことを理解したものとみなされます。


