Blog Zscaler
Recevez les dernières mises à jour du blog de Zscaler dans votre boîte de réception
Threat Intel, SSL Inspection and Other Considerations: A Real-World Checklist for SSE
Somewhere in the middle of your cloud-first journey, there’s a moment that doesn’t feel like progress.
Despite users, apps, and data being decentralized and spread everywhere, most real-world trouble still walks through the same front door it always has: the open web.
The web now hosts SaaS, partner portals, developer tooling, and a growing pile of AI assistants—almost all wrapped in TLS/SSL. Great for privacy. Brutal for visibility. Without scalable inspection, encryption becomes a cloak for lateral movement, malware delivery, and data exfiltration.
Secure Service Edge (SSE) adoption is the logical response to this shift. But it only wins if your Secure Web Gateway (SWG) can take a punch.
So ask yourself: will your SSE-based platform hold up in production? Validate it against this five-point checklist.
1. The Encryption Test: Can You Inspect Without Collapsing?
With over 87% of threats now delivered via encrypted channels, SSL/TLS inspection is no longer optional— it’s baseline defense.
However, the architectural challenge is not simply capability, but capacity.
Legacy appliances and their virtualized equivalents are bound by fixed compute resources. When inspection load spikes, they force a choice: throttle the user or bypass security.
A cloud-native proxy architecture eliminates this trade-off by decoupling inspection from physical hardware limits, dynamically scaling to inspect traffic without creating a bottleneck.
Considerations for your SSL/ TLS inspection:
- Decrypt coverage: What % of relevant TLS SaaS sessions do you inspect—by app and by category?
- Granular TLS controls: Do you have control over specific apps to be decrypted/ bypassed (SNI-based)? Are these policy controls consistent over web and SaaS applications?
- Certificate reality: How is certificate distribution being managed across all managed and unmanaged devices? How are trust store updates being propagated across VDI?
- Performance + failure mode: What’s the p95 added latency at normal and peak, and is fail-open vs. fail-closed configurable by risk tier?
- Exception governance: For every application bypass, can you prove an owner, a reason, and an expiry/review cycle—with reporting?
- Protocol roadmap: Beyond TLS 1.3, what’s your plan for QUIC/HTTP/3 visibility and mitigation when full inspection isn’t possible?
2. The Traffic Flow Test: Local Breakout vs. The Hairpin
In a distributed world, network architecture equates to security architecture.
If users in Europe have to hairpin through a U.S. hub just to reach a European SaaS endpoint, you’re paying a latency and bandwidth tax with no security upside.
That’s not SSE. That’s hub-and-spoke with a new outfit.
A true Zero Trust Exchange model inverts this. It routes users to the nearest point of presence, applies security policy instantly, and connects them directly to their destination—so the infrastructure stays invisible to attackers and users connect to apps, not networks.
Considerations:
- Nearest enforcement point: Are you fully utilizing a truly global presence of at least 150+ Datacenters or relying on a few “regional hubs” that are recreating choke points?
- Real latency evidence: Do you have traceroutes and real-user latency across multiple geos and ISPs (not vendor demo networks). If you’re a Zscaler customer, use ZDX to baseline the user-to-app path (device → Wi-Fi/ISP → Zscaler cloud → SaaS/app) and show where the delay lives.
- One policy model, everywhere: Does policy follow the user—or do rules drift by geography, and do you have audit trails for what was applied?
- Predictable egress steering: Are you able to comply with regional and SaaS requirements such as in-country logging and Dedicated IPs with your own IPs being used if necessary? Are your users viewing content in their local language with little impact on performance?
3. The Operational Reality: Reducing the Burden or Relocating It?
Traditional appliance-based models force you to manage dozens of boxes—patching, upgrading, monitoring. That multiplies operational risk and burns scarce engineering time.
A lot of “modern SWG” projects stall because they just relocate the same burden into cloud instances and call it progress.
A cloud-native SWG removes the need for distributed firewalls and point products, cutting hardware spend and patch overhead—while the platform updates continuously as threats evolve, without forklift upgrades.
Considerations:
- Ownership boundary: Do you have a clear demarcation between your service provider’s responsibilities and your own? Do you still own uptime/ scaling and patching after moving to the service?
- No infrastructure runbooks: If you are still scheduling reboot windows or kernel patches, are you running software, or consuming a service?
- Elasticity under stress: Has your M&A cutover been simplified? Do you still have to plan for infrastructure to cater to office reopening spikes?
4. The Data Protection Test: Inline Enforcement
SWG isn’t “web filtering” anymore. It is business protection. Modern exfiltration doesn’t look like “upload to a sketchy site.” It looks like sanctioned SaaS uploads, mis-shared links, copy/paste into AI assistants, and normal workflows moving sensitive data to places where work actually happens.
The question is: Can your SWG enforce data protection policies inline, not after the fact?
Considerations:
- Inline controls for web + SaaS sessions: Is enforcement happening inline in the SWG path—or are you leaning on API, after-the-fact scanning that shows up after the damage is done?
- Unified DLP policy + engine: Are the same classifiers, dictionaries, and fingerprinting used across DLP/CASB/email and enforced inline for web + SaaS—or does “HR data” trigger in email but slip through the browser?
- Detection depth: Do you truly cover PII/PCI/PHI, exact data matching, document fingerprinting, and regional identifiers tied to your regulatory footprint—and are decisions context-aware (user + device posture + app + action)?
- GenAI coverage: As AI adoption grows, does your SWG inspect prompts, uploads, and browser sessions for web AI tools—inline, in real time?
Proof scenarios to run (don’t skip these):
- Upload source code to a developer SaaS
- Paste customer data into a web-based AI assistant
- Sync sensitive files to cloud storage
Is your SWG able to prevent all of the above? If the result is “we detected it in logs,” you didn’t protect anything.
5. The Threat Intel Test: Cloud Speed vs. Patch Speed
Finally, look at the speed of your defense. Does threat intelligence move fast enough to matter?
In an appliance model, a new zero-day often means waiting on a vendor patch—then testing it, then rolling it out across your fleet.
In a cloud-native platform, a threat blocked in one geography (say, an attack on a manufacturing plant in Asia) can be turned into global protection—automatically and immediately.
Considerations:
- Propagation speed: How quickly are cloud detections enforced for your tenant? Does it take minutes or days?
- Real examples, with timelines: Is your SWG sharing recent campaigns, what triggered the update, and how fast protections rolled out?
- Global consistency: Is the same protection available across geographies and user populations?
- Your signals at cloud scale: Do your IOCs/blocklists go live quickly without turning into policy spaghetti?
- Learning loop + telemetry:Third-party validation: Beyond vendor claims, what independent evidence validates security effectiveness and real-world impact—e.g., published lab testing, peer-reviewed evaluations, external audits, analyst assessments, or customer-run benchmarks with documented methodology?
- Public proof trail: A good benchmark is the kind of public, time-stamped research stream Zscaler ThreatLabz publishes—ongoing security research write-ups and annual reports that document what changed and when.
Conclusion: SSE in production vs. on PowerPoint
SWG isn’t making a comeback because anyone is nostalgic. It’s central again because the web is where your business runs—and where risk shows up first.
So the question isn’t “Do we still need SWG?” It’s whether your SWG model can:
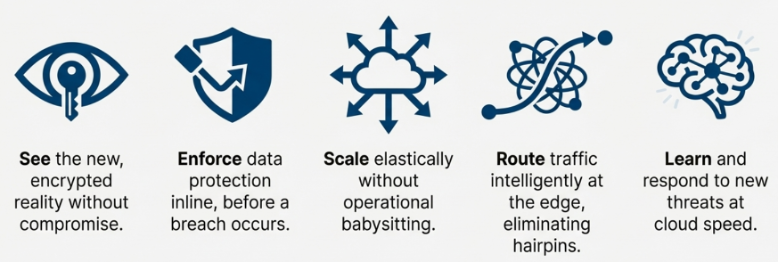
If the answer is no… your SSE strategy is meant to look good only on a slide.
Want to talk to an expert? click here.

Cet article a-t-il été utile ?
Clause de non-responsabilité : Cet article de blog a été créé par Zscaler à des fins d’information uniquement et est fourni « en l’état » sans aucune garantie d’exactitude, d’exhaustivité ou de fiabilité. Zscaler n’assume aucune responsabilité pour toute erreur ou omission ou pour toute action prise sur la base des informations fournies. Tous les sites Web ou ressources de tiers liés à cet article de blog sont fournis pour des raisons de commodité uniquement, et Zscaler n’est pas responsable de leur contenu ni de leurs pratiques. Tout le contenu peut être modifié sans préavis. En accédant à ce blog, vous acceptez ces conditions et reconnaissez qu’il est de votre responsabilité de vérifier et d’utiliser les informations en fonction de vos besoins.
Découvrez d'autres blogs Zscaler
")
Break Free from Appliance-Based Secure Web Gateway (SWG)

The SSE Accolades Keep on Coming

The Benefits of Adopting Zscaler’s Multimode CASB
Recevez les dernières mises à jour du blog de Zscaler dans votre boîte de réception
En envoyant le formulaire, vous acceptez notre politique de confidentialité.