
 I decoded this suspicious object using the pdf-parser tool and found obfuscated JavaScript code inside. Here is what the decoded code looked like:
I decoded this suspicious object using the pdf-parser tool and found obfuscated JavaScript code inside. Here is what the decoded code looked like:
 The code is heavily obfuscated to hide the actual exploit code. There were 2 calls to the “eval()” function. The first one extracted one variable (i.e. K9U8Zm8NS4) from another (i.e. KeNJ148) which is then XOR’ed with 2 other variables which are nothing but some secret key values. Confused? Hang tight. After that there is a call to a “String.fromCharCode” function on the final XOR’ed variable (i.e. e208xh). After initial analysis of the code, I pasted the code into Malzilla to see the final output of the obfuscated JavaScript code and found that Malzilla was unable to decode it. Something wasn’t going right for Malzilla.
The code is heavily obfuscated to hide the actual exploit code. There were 2 calls to the “eval()” function. The first one extracted one variable (i.e. K9U8Zm8NS4) from another (i.e. KeNJ148) which is then XOR’ed with 2 other variables which are nothing but some secret key values. Confused? Hang tight. After that there is a call to a “String.fromCharCode” function on the final XOR’ed variable (i.e. e208xh). After initial analysis of the code, I pasted the code into Malzilla to see the final output of the obfuscated JavaScript code and found that Malzilla was unable to decode it. Something wasn’t going right for Malzilla.
I figured it out that there are some strings or function like “this.numPages” used inside the code and because of that, Malzilla was unable to decode it. If you observe, this is the first key (i.e. l46bQ8A) which is used to XOR with the original variable (i.e. e208xh). I changed the variable which was using the “this.numPages” function manually to integers such as 1, 2 etc. and tried decoding it once again. Finally, Malzilla started decoding it but the output was still not legible – I’d clearly missed some additional decoding routines. I then realized that there were 2 keys being used for XORing - one was hard coded with value “189” while the other was taking a value from the “this.numPages” function. This function returns the number of pages present inside the PDF file. That means whatever values I was passing to the variable manually, wasn’t correct and the script was unable to decode it. I re-opened the PDF file to search for object which contained the number of pages used inside the PDF and found the exact count,

There are “20” pages inside this malicious PDF file and this is turned out to be the first key which was used for XORing with the original variable. Now I changed the variable value to “20” and tried to decode the JavaScript. Finally, everything went according to plan and malzilla decoded the JavaScript into readable code. This was a rather unique trick used by the attacker to encode/decode the malicious JavaScript leveraging the “this.numPages” function. Once that challenge was solved, the rest was easy to understand as the skeleton of the final code was using a familiar heap spray technique and targeting known Adobe vulnerabilities. Here is the final decoded JavaScript:
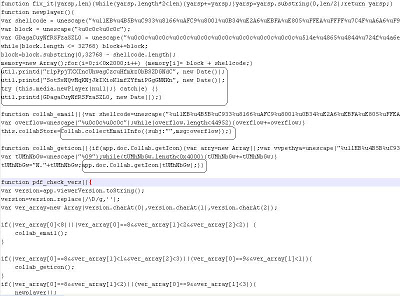
The exploit was targeting 3 different vulnerabilities.
1) mediaNewplayer CVE-2009-4324
2) collectEmailInfo CVE-2007-5659
3) CollabgetIcon CVE-2009-0927
The detection for this PDF file remains very poor. Here is the Virustotal result for this file – currently, only 6 of 42 AV vendors detect it. This is a really interesting case as the “key” is actually a component of the PDF file and this is deliberately used by the attacker so that the manual decoding becomes difficult for researchers. Even Webpawet failed to decode it properly. This time attacker has used “number of pages” inside the PDF as a key to decode the malicious script code. I expect that we’ll see similar tricks going forward.
What’s your key?
Umesh




