Why SLAs?
Service level agreements (SLAs)—in the context of this blog—are a cloud security vendor’s expression of confidence in its ability to deliver a resilient, scalable, and high-performing service. SLAs became more common as SaaS solutions expanded in popularity, providing organizations assurances about their service levels, such as performance and availability, across a large pool of shared resources. While SLAs tend to be a focal point for lawyers, all stakeholders in a purchasing decision should understand a vendor’s SLA to:
- Identify business impacts of reliability, speed, and overall user experience associated with the service
- Quantify risk by understanding what exclusions exist in your agreement
- Differentiate between industry leaders and innovators over other vendors using savvy wording to create an illusion of quality SLAs
In this post, we’ll dive into SLAs for cloud security vendors, for Zscaler and others, to:
- Find Zscaler’s secret ingredient for industry-leading SLAs
- Uncover and analyze the most important components of SLAs, with a specific deep dive on the proxy latency SLA
- Equip you with evaluation criteria to differentiate between industry-leading SLAs and other vendors’ SLAs, too commonly riddled with exclusions that undermine the objective of the SLA
Zscaler’s approach to SLAs: identifying the secret ingredient
Plain and simple, the secret ingredient to industry-leading SLAs is an industry-leading security cloud. You can’t skip straight to the SLAs without being able to back them up.
At Zscaler, backing up our industry-leading SLAs is the result of more than a decade of pioneering, building, and operationalizing the world's largest security cloud designed to secure mission-critical traffic. . We have seen many vendors try and replicate our approach, masking their lack of technical differentiation in SLAs that seem good on the surface but are misleading in practice.
Here are some primary attributes of other vendors:
Point product CASB vendors attempting to expand into new markets:
- Platform designed for simple tasks like out-of-band scanning of SaaS apps using REST APIs as opposed to processing mission-critical traffic at line-rate, which requires a very different approach and DNA
- Product strategy focused on announcing checkbox “features” ahead of marquee analyst reports (i.e. Gartner MQ) rather than discovering and solving unique customer problems
- Architectures built on the Squid proxy open-source project, which has a long history of failing to scale
Legacy hardware vendors trying to stay relevant:
- Repurposing single-tenant virtual appliances on IaaS (i.e. GCP, AWS) with limited compute data centers, a shared-responsibility model, and unreliable availability
- Service chaining by bolting on existing and new services that introduce complexity and latency with every additional capability
- Irregular service and OS updates for VM firewalls (e.g. 6-9 months for OS updates to migrate from physical firewalls to VM firewalls hosted in the public cloud)
These approaches have proven to have significant limitations for delivering a quality service and the resulting SLAs. We’ll explain these limitations in more detail below.
Proud to show our scale
When evaluating a vendor’s SLAs, you are, in essence, evaluating the strength of their cloud platform. Without publicly accessible data on scale and performance, how can you truly evaluate the platform and resulting SLAs? Zscaler is the only vendor in the industry to publicly share data to back up our scale and performance claims.
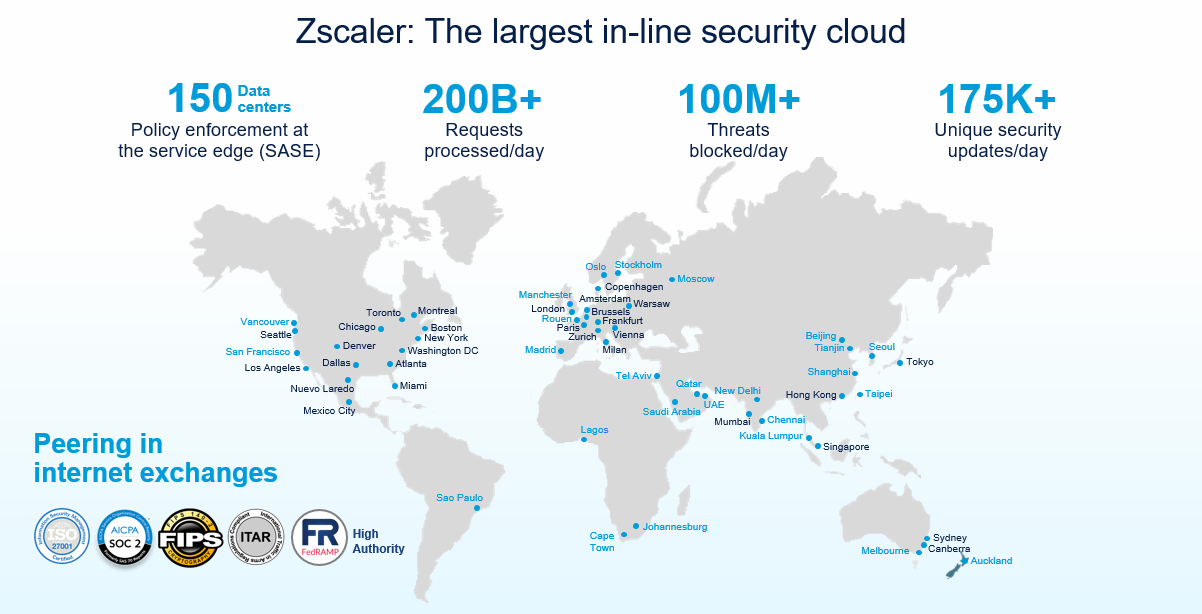
Zscaler’s global footprint: 100% compute data centers (no on-ramps or vPoPs)
We are so confident in our scale claims that we want you to see them for yourself, at any time, with real-time data. Check out the Zscaler Cloud Activity Dashboard to see these up-to-the-second metrics.
Food for thought:
Why does no other vendor provide public data or metrics on their scale or how their cloud operates? (pro tip: a picture of a race car to symbolize speed does NOT count as proof)
Zscaler’s SLAs: high availability, superior security, and blazing fast speed
That’s the simple essence of the Zscaler Internet Access (ZIA) SLAs as described on our product sheet. Operating the industry-leading security cloud mandates industry-leading SLAs:
1. The (customer-friendly) high-availability SLA
In general, this is where vendors battle on their number of 9’s (you’ll see language like “5-nines,” meaning 99.999%, of availability used commonly). The more 9’s, the stronger the availability commitment. For example, with 99.9% availability, a vendor guarantees that its service will be down for no more than 525 minutes in a year: (1-99.9%) x 525,600 (525,600 is the number of minutes in a year). A vendor with five 9’s, or 99.999%, will commit to less than 6 minutes of downtime per year.
If you read our SLAs carefully, you’ll notice that Zscaler offers an innovative agreement based on the percentage of lost transactions as a result of downtime or slowness rather than the percentage of time that the service was not available. This customer-friendly SLA aligns closely with the actual business impact of downtime and even provides credits back when the service is 100% available, but the customer is experiencing a slowdown due to unexpected congestion.
Food for thought:
If your transactions dropped by 20 percent due to congestion, would your vendor claim that the service was 100 percent available?
This is where lift-and-shift vendors, who run their legacy single-tenant VMs on IaaS, struggle the most due to the lack of control and unpredictability of the underlying infrastructure. It is fairly common to see these vendors crowd their SLAs with a long list of exclusions, defeating the purpose of the SLA.
In this example, a legacy NGFW vendor excludes unplanned upgrades from the SLA, making it worthless:

Food for thought:
If the cloud goes down unexpectedly and without notice, but that doesn’t count as downtime, then what does? Isn’t that the definition of downtime?
In another example, the same legacy NGFW vendor excludes scale events from their SLA:

Food for thought:
Isn’t a primary goal of cloud-delivered services to take away the overhead and anxiety of scaling?
2. The 100% Known Virus Capture SLA (superior security)
A hyper-scale proxy should not only deliver a blazing fast user experience, but also superior security without shortcuts. Had all we needed to do is pass packets from point A to B without scanning, we could have delivered 0ms latency, but with terrible security. The Known Virus Capture SLA is an industry-only and industry-first that again puts our money where our mouth is on superior security. We commit to preventing 100% of all known malware/viruses from leaking through our platform. For every miss, you’ll get some credit.
Other vendors take shortcuts in their SLAs by just passing through traffic "known to be safe", such as CDNs and file-sharing services, without any scanning due to architectural, scalability, or resiliency limits. This thinking is becoming increasingly antiquated in our ever-changing threat landscape as threats delivered over trusted, reputable sources continue to rise.
Food for thought:
Are you willing to consider all traffic from CDNs, public cloud providers, or file-sharing services as trusted?
3. The Low Proxy Latency SLA (blazing fast speed) -
Inspecting encrypted traffic (with no limits) and applying threat and data loss prevention engines simultaneously consumes CPU cycles—that’s physics. Here’s where we commit to extremely effective and efficient security and data protection with superior user experience.
Deep dive on proxy latency SLA
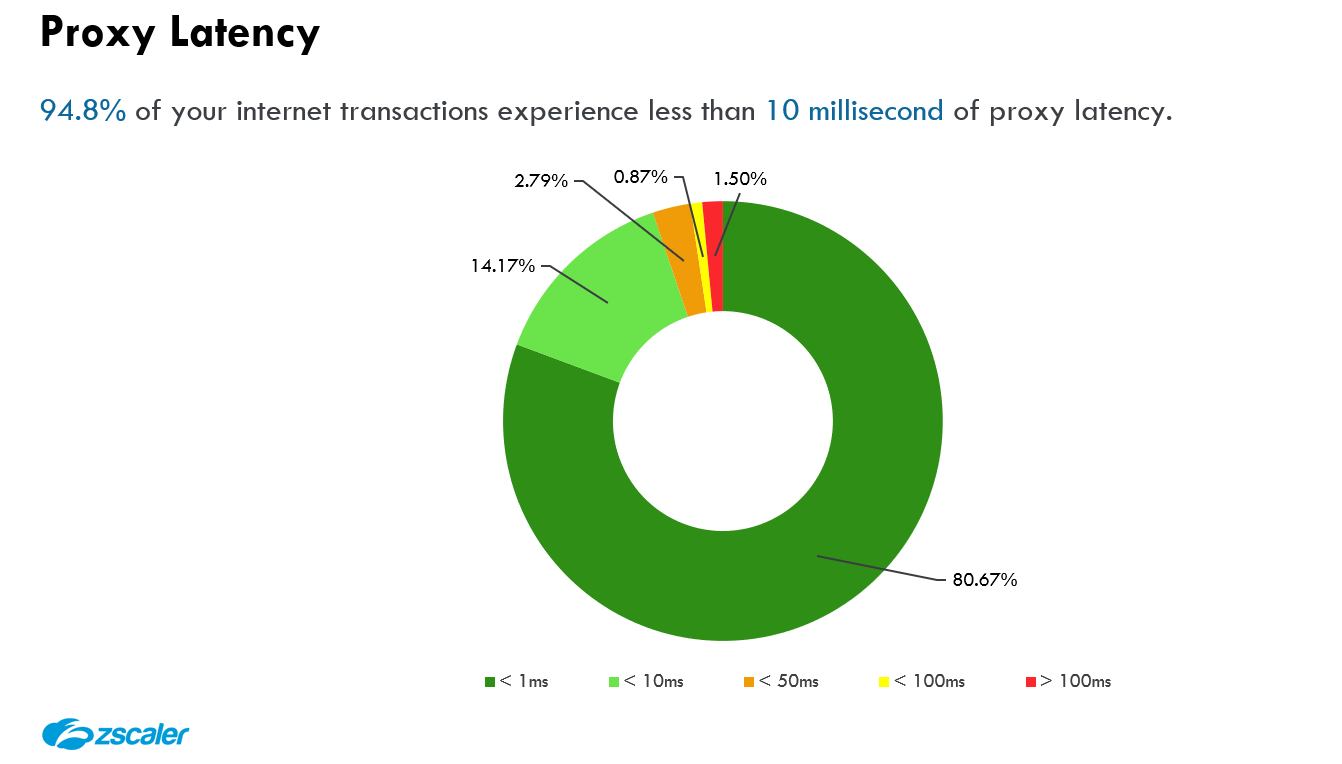
When optimizing user experience, you must consider both network latency and proxy latency. Network latency optimization is a topic for another blog, but briefly, network latency is the time between the client and Zscaler plus the time between Zscaler and the server. Both network latency and proxy latency are heavily optimized through our extensive service edge presence and exchange peering capacity. However, the focus of this section is proxy latency:

Proxy latency is a layer 7 metric that reflects the added time (in milliseconds) introduced by the proxy to scan the HTTP/S request, plus the added time to scan the HTTP/S response. In the above diagram, the proxy latency is Xms (request) + Yms (response). As a layer 7 proxy, Zscaler executes many security and data protection engines both on the request headers/payload and the response headers/payload, so it’s important to capture both sides.
Can this proxy latency be eliminated? No. Because of, well, physics—scanning every transaction requires CPU cycles. Can this proxy latency be optimized? Yes, and we’ll briefly discuss this later in the blog.
The right way to deliver industry-leading proxy latency SLAs
Unfortunately, other vendors are notorious for their creative fine print for SLA exclusions that defeat the purpose of the SLA. Make sure you understand what exactly a vendor is excluding, how they calculate their latency, and that it doesn’t feel too good to be true.
1. Include threat and DLP scanning
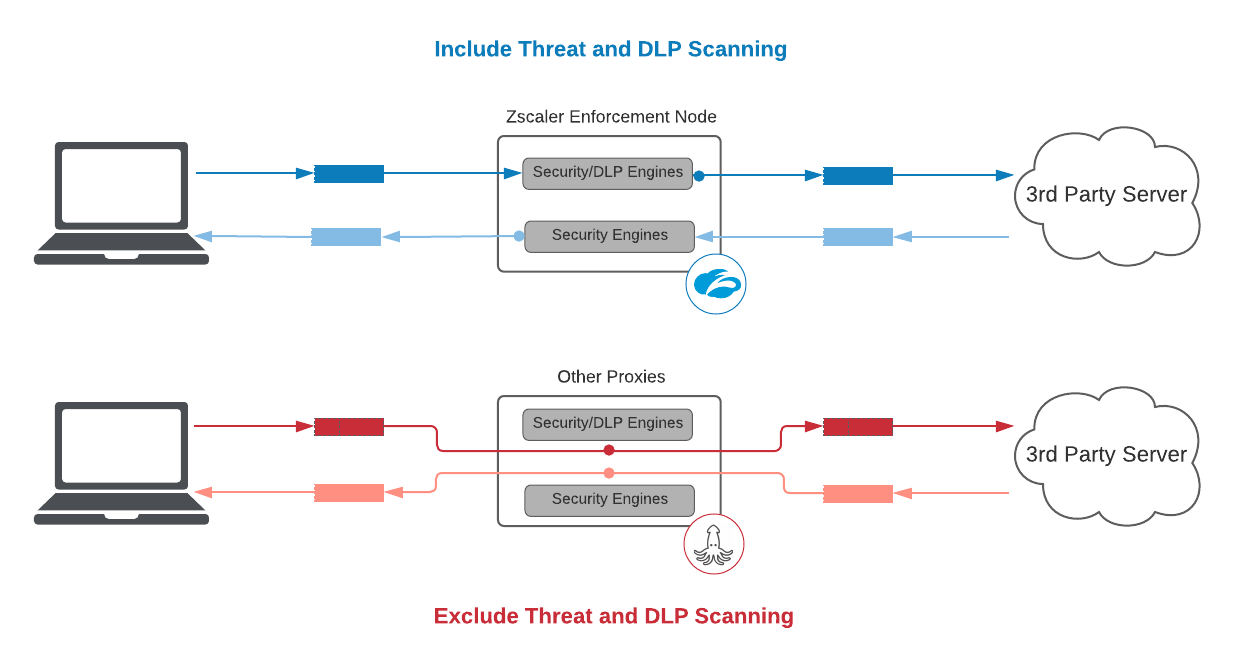
As a security service, excluding threat and DLP scanning defeats the purpose of the SLA
Passing packets from one side to the other without doing any work is “easy”. Be cautious when vendors offer latency numbers that appear too good to be true. In fact, had Zscaler wanted to offer an SLA with no threat or DLP scanning, we could offer an agreement of 25ms and 5ms for the 95th percentile for decrypted HTTPS transactions and for plain text HTTP transactions, respectively—2x better than other vendors, but we believe it’s not a relevant measure and highly misleading to our customers.
For example, a point product CASB vendor, not built for inline traffic processing, shows its true colors in the fine print:

A proxy latency SLA must not exclude the added time introduced by its engines.
2. Provide transparency
The proof is in the pudding—trust, but verify all the latency claims of your cloud security provider.
A proxy latency SLA must be supplemented with vendor-provided reports and transaction-level metrics to hold the vendor accountable. No Data = No SLA.
Transaction-level detail is the real proof of the impact latency imposes and is critical for transparency and for troubleshooting. Combining poor architecture choices with aggressive SLAs puts other vendors in a tough spot to meet this requirement:
- Point product CASB vendors forced to expand into new markets: By relying on an unscalable, open-source proxy project, there is no enterprise-grade logging plane that can capture transaction-level logs (SOC folks reading this, let that soak in). SLAs cannot be reported at the transaction level with this approach even if they wanted to...period.
- Legacy hardware vendors trying to stay relevant: Service chaining various functions with firewall VMs on IaaS results in disaggregated latency figures and the inability to report end-to-end proxy latency in real-time.
As a result of either the inability or unwillingness to provide transparency, a known CASB vendor has been forced to use sneaky tactics to mask latency problems behind an hourly average. Since they can’t log at the transaction level, the average would be artificially skewed down during high variability hours.
Zscaler was built with transparency in mind. We are both willing and able to provide our customers with the visibility we owe them:
Zscaler-provided Quarterly Business Review (QBR) latency report

Zscaler’s Web Insights Log Viewer with transaction-level proxy latency visibility
3. Focus on proxy transaction latency vs. firewall packet latency
Packet latency portrays an incomplete picture of latency, especially in our web-centric world.
Since we are talking about proxy latency, I’ll keep this relatively brief, but it’s important to understand the fundamental difference. Packet latency is a measure of the time it takes a physical or virtual firewall appliance to process the request packets (input to output time), however, this metric is flawed. Measuring the request processing time is only a fraction of the overall transaction latency and misses out on the more critical aspect of latency, receiving the information back. By nature, most web traffic is GETs with small payloads but large responses; this is a serious misunderstanding of how latency should be measured in our web-centric world.
Zscaler’s secret ingredient for best-in-class low proxy latency
Scaling up and out the cloud’s infrastructure is the first step, but the optimal solution relies on the right underlying architecture. Zscaler scans every single packet and does so extremely efficiently with parallel security services called Single Scan, MultiAction (SSMA):
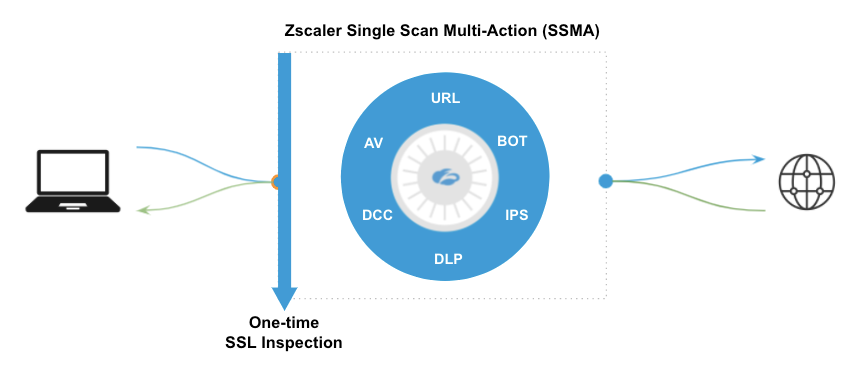
Zscaler’s Single Scan Multi-Action Engines working in parallel
SSMA represents the best of what security practitioners have been asking the industry to implement for decades—a single platform that balances best-in-class security and a fast user experience. This is what Gartner calls “single-pass inspection of encrypted traffic and content at line speed” in the SASE framework.
With legacy architectures, whether service chaining appliances, cloud-based services, or a mix of both, packets need to leave memory from one virtual machine (VM) to another VM in a different data center or completely different cloud. You don’t need to understand physics or networking very well to see how that’s inefficient and wildly complex.
Zscaler was built with a cloud-native architecture that places packets in shared memory in highly-optimized, purpose-built servers, designed for an optimized data path. Even more important, is that all of the CPUs on a Zscaler node can access those packets at the same time. By having dedicated CPUs for each function, all of the engines can inspect the same packets at the same time (hence the name, Single Scan, MultiAction). This ensures there is no added latency from service chaining, allowing the Zscaler node to make policy decisions extremely quickly and forward the packets back out to the Internet.
In summary, repurposing legacy virtual appliances and white-labeling open-source proxy projects with bolted-on engines doesn’t work. There is far too much legacy technical debt to address and make up when taking these approaches.
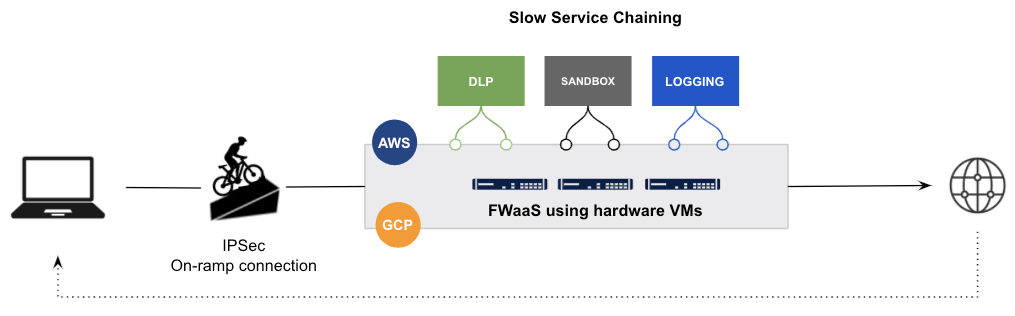
Example of a legacy vendor repurposing legacy FW VMs on IaaS with service chaining
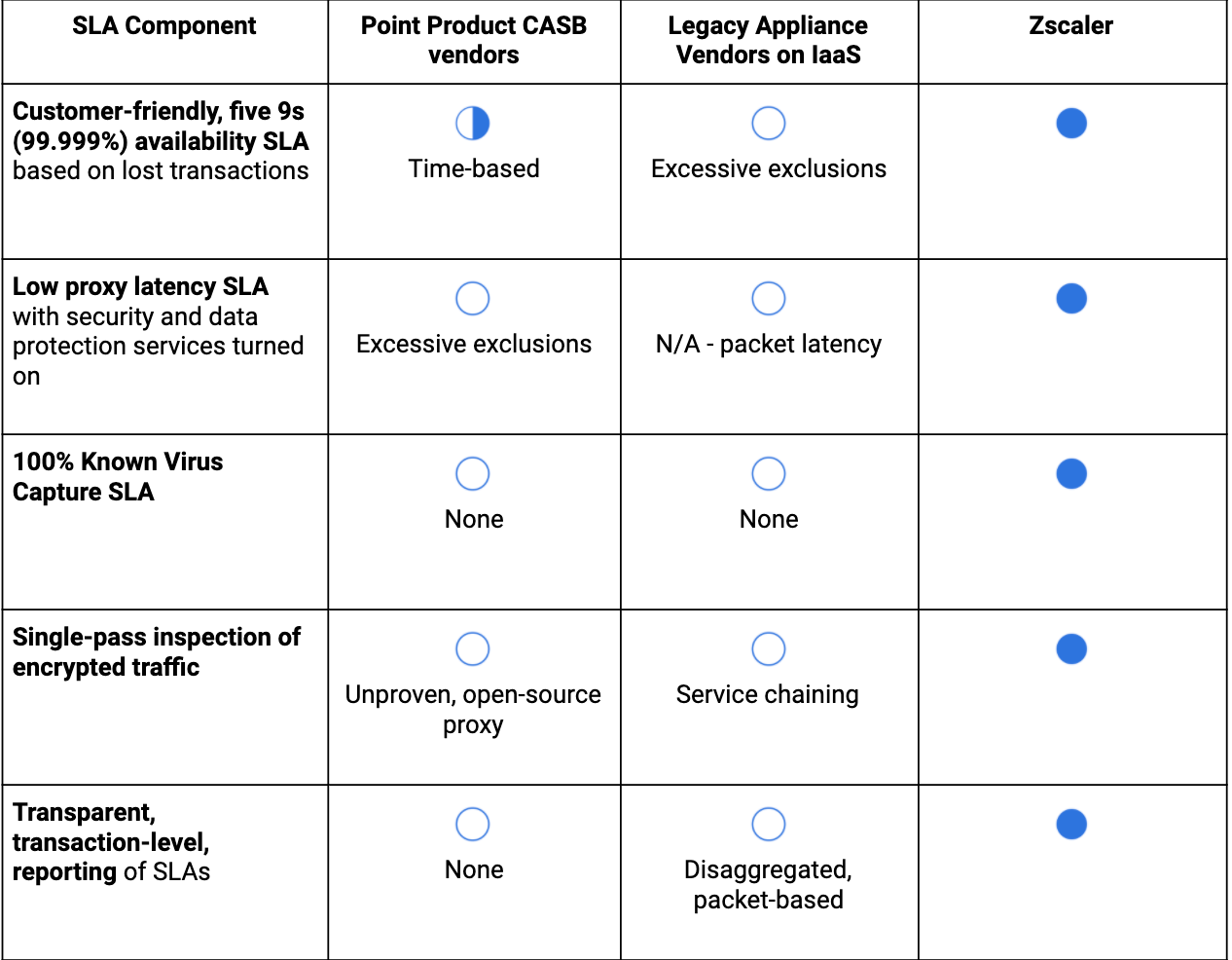
Keep your vendors honest about their SLAs
Here’s a little advice on how to put this information to work. Many of our customers and prospective customers focus their SLA discussions with vendors around availability, which is a highly important question to ask but leaves gaps in an analysis of a vendor’s service.
Below is a quick table that you can use to identify key components of SLAs you will be shown: