
Gone are the days when a phishing page was a single page designed to capture user credentials. Phishing kits have become sophisticated and advanced to evade detection and look more legitimate to the user. In this blog, we will discuss some of the latest evasive and anti-analysis techniques used by these phishing kits.
Techniques to make phishing pages look more legitimate
1. Verification of payment card number before accepting
Many phishing campaigns related to banking, online shopping, or account upgrades ask victims to provide payment details to complete their online transactions. In such cases, most of the phishing campaigns simply check the length of the card number (debit or credit) provided by the victim and restrict them to 16 digits to prevent random details from being entered. In some cases, attackers go one step further, using online verification services to ensure that the victim enters the correct payment information.
The information about the institution that issued a particular card can be checked with the initial six or eight digits of the card number, which is called an Issuer Identification Number (IIN). Many online services provide APIs to check the IIN of a card. The screenshot below shows one such case.
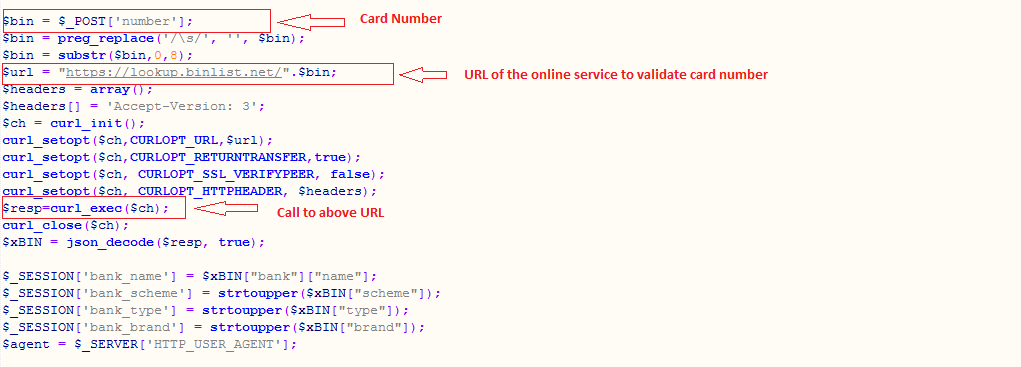
Fig. 1: Request to check IIN information of the payment card number shown in the source code
2. Changing the language of phishing content based on victim’s geolocation
Most phishing campaigns are designed in one language based on the probable victims of the attack. Such phishing pages only work in a particular region or country according to the language it is designed in. Like legitimate websites that are often "localized," there are a few phishing campaigns that instead of using one language deliver phishing content based on the geographical location of the victim, determined after the victim’s IP is checked.
Below is one such campaign which first checks the victim’s geolocation; all the main strings in the phishing page are variable with values that depend on geo-location.


Fig. 2: The main heading variable on the phishing page


Fig. 3: Values of the phishing page title, heading, and submit button based on geolocation
Evasion and anti-analysis techniques
1. One-time access to the phishing page
We have seen instances where phishing pages are accessible only once; upon revisiting the page, it redirects the user to other websites. Below is one such campaign.

Fig. 4: The victim's IP address is logged after checking if it is the first visit

Fig. 5: File onetime.dat store log of all victims’ IP addresses
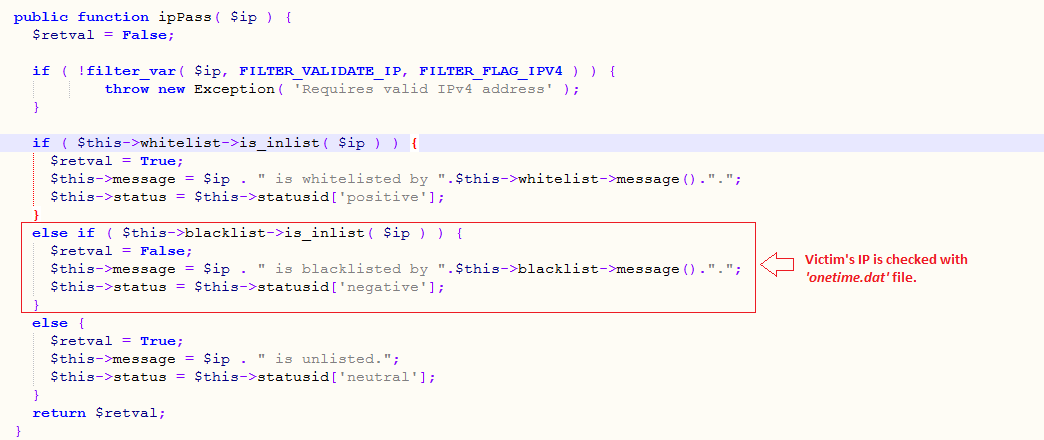
Fig. 6: A victim's IP address is checked against the IP address in the file onetime.dat
When a client visits phishing pages, such as the one discussed above, the IP address of the client gets logged in a file on the first visit. Each time a client visits such phishing pages, the client’s IP address gets checked against the list of IPs of clients that previously visited. Based on the results of that check, access to the phishing page is either granted, results in a “Page not found” message, or the client may be redirected to other websites.
2. Proxy check using online services
Recently, many phishing kits have included a hardcoded denylist for certain IP addresses, user-agents, and hostnames known to be used by security researchers and security companies. If the client attempts to connect with a denied IP or user-agent, the phishing content will not be served. In some cases, along with the list of hardcoded IP addresses, the client’s IP is checked using some online services to see whether or not it is a proxy.

Fig. 7: Source code using an online service to check the client's IP address for a proxy

Fig. 8: Phishing page for the above-discussed campaign
3. Creating a new random name directory on each visit
To make it more difficult to detect phishing campaigns, some campaigns create a new random name directory each time and the phishing page is hosted on this random directory. Below is the analysis of one such campaign.
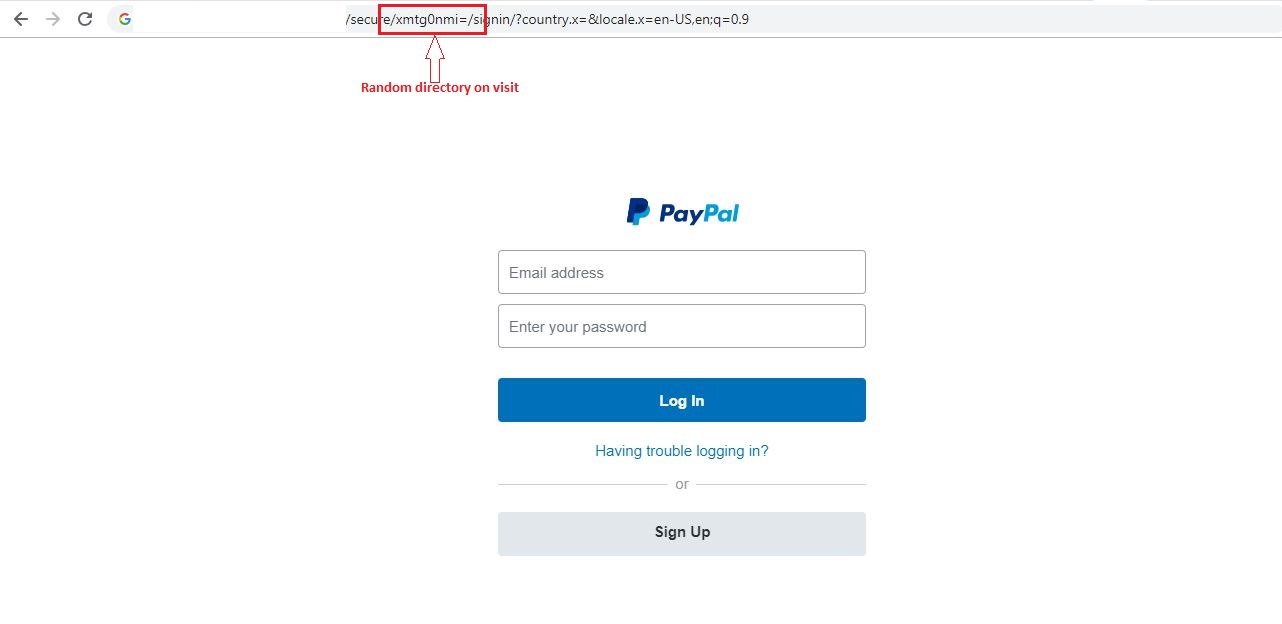
Fig. 9. Random name directory is shown on a phishing page
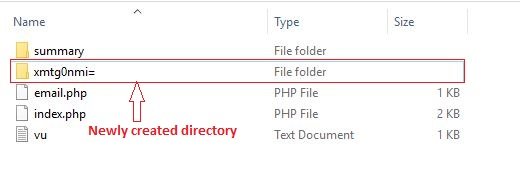
Fig. 10: Newly created random name directory in a web server

Fig. 11: Source code to generate a random name directory on each visit
4. Creating a new random name file on each visit
A few phishing kits were found to be creating a new random name file on each visit to make it difficult to identify as a phishing site. Below is the analysis of one such phishing kit.
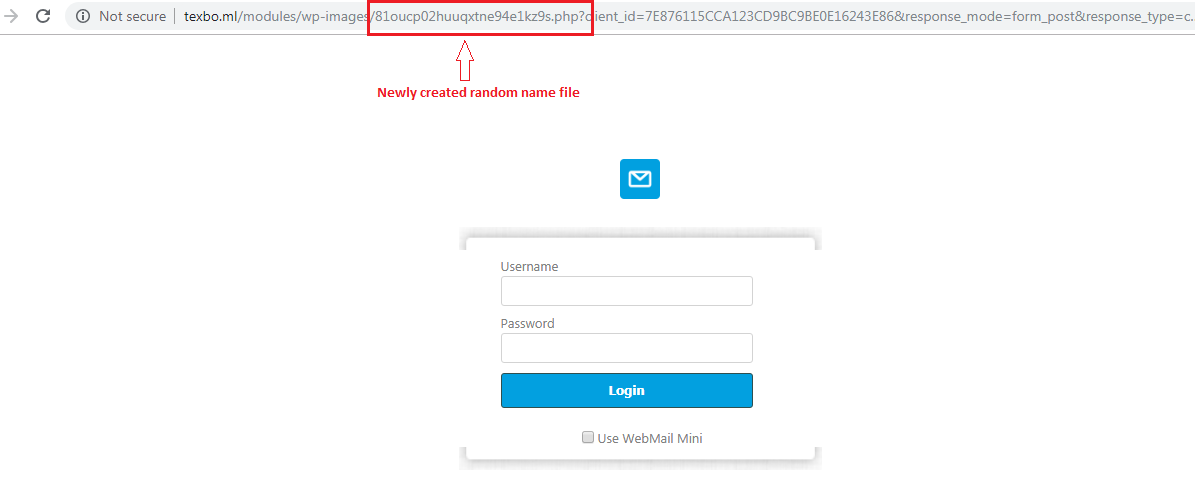
Fig. 12: Random name file in URL is shown on a phishing page

Fig. 13: Source code to generate a random name file on each visit
5. Random values for HTML attributes on each visit
To make a phishing page hard to analyze and detect, the page values of HTML attributes are generated randomly upon each visit, as shown in the phishing campaign depicted below.
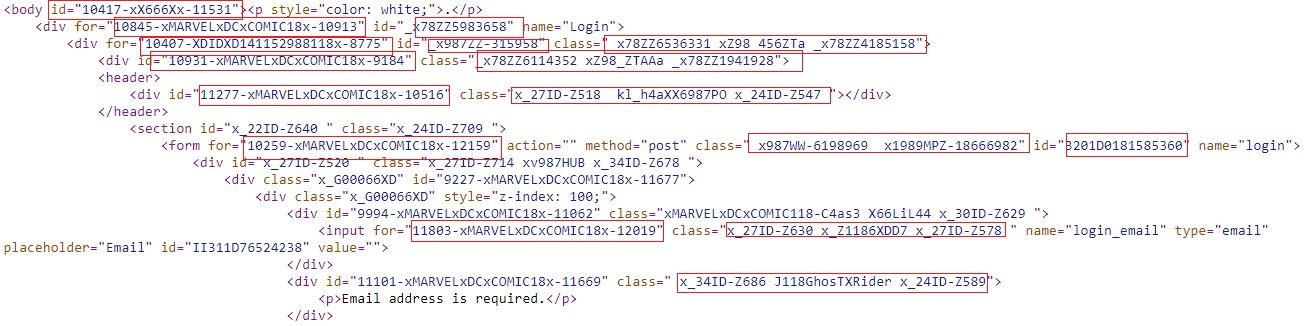
Fig. 14: Randomly created values for HTML attributes
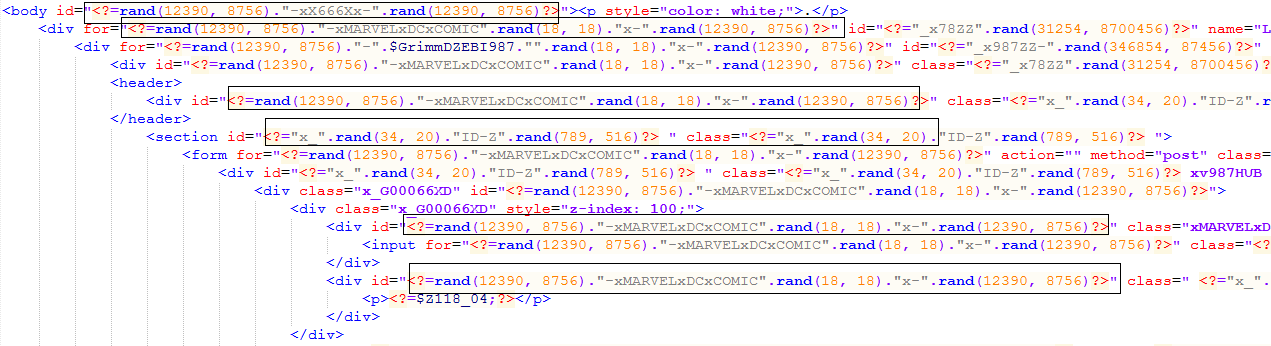
Fig. 15: Source code to generate random values for HTML attributes

Fig. 16: Phishing page related to the above-discussed campaign
Conclusion
Phishing attacks have been on the rise for a few years, but we’re seeing changes in attackers’ methodologies. As end users become more careful about clicking suspicious links or opening unknown attachments, attackers have also upped the ante by evolving the way in which the phishing content is delivered, and they’re leveraging new tactics to make the phishing pages remain undetected for longer periods.
Zscaler ThreatLabz actively tracks new and evolving phishing campaigns and protects customers from these types of attacks.




