Exploit kits are a much more common threat on the web than they used to be. In order to evade detection, the kits frequently contain logic to obfuscate, or hide, the meaning behind the content that they serve to the victim. Additionally, with each visit to the exploit page, the obfuscation techniques will differ slightly so that static, content signatures will be unable to detect the threat. Other threats contain obfuscated JavaScript (JS) which sets up the page to exploit a vulnerability and launch a payload (for example, "spraying" the heap with shellcode). Still other threats inject obfuscated JS into legitimate sites, which after decoding embeds a hidden (0-pixel) IFrame to malicious content. As we have seen in the past, the JS encodings vary greatly with each incident, and many instances are encoded multiple times and may contain non-standard JS (reference past blog posts, such as "More and more obfuscation being used in the malicious scripts"). While some signatures have been written for things like generic heap spraying and other maliciousness within obfuscated JS, the bad guys are constantly updating their tactics to evade detection. Anyway, the point that I'm getting at is that scalable (think ISP), inline deobfuscation of JS is something that is *very* difficult to implement.
Exploit kits are a much more common threat on the web than they used to be. In order to evade detection, the kits frequently contain logic to obfuscate, or hide, the meaning behind the content that they serve to the victim. Additionally, with each visit to the exploit page, the obfuscation techniques will differ slightly so that static, content signatures will be unable to detect the threat. Other threats contain obfuscated JavaScript (JS) which sets up the page to exploit a vulnerability and launch a payload (for example, "spraying" the heap with shellcode). Still other threats inject obfuscated JS into legitimate sites, which after decoding embeds a hidden (0-pixel) IFrame to malicious content. As we have seen in the past, the JS encodings vary greatly with each incident, and many instances are encoded multiple times and may contain non-standard JS (reference past blog posts, such as "More and more obfuscation being used in the malicious scripts"). While some signatures have been written for things like generic heap spraying and other maliciousness within obfuscated JS, the bad guys are constantly updating their tactics to evade detection. Anyway, the point that I'm getting at is that scalable (think ISP), inline deobfuscation of JS is something that is *very* difficult to implement.
One way of coping with this problem is to implement a number of efficient checks to analyze and score the JS inline for likelihood of maliciousness (JS heuristic). Pages that meet a certain score threshold may have additional inspections done or the page may be blocked outright. After doing some research and testing against some malicious and benign sites, I came up with a small number of checks that can be implemented inline and also produced some compelling results. While I won't divulge all of the "secret sauce", I wanted to share two pretty interesting checks that I'm doing against JS.
Shannon Entropy Scoring
Entropy is the "measure of how organized or disorganized a system is" (wikipedia) - in other words, it is the amount of randomness in something. Shannon entropy is expressed in terms of probabilities, which describes the the number of yes/no questions (bits) needed to determine the content of a message (the more entropy in a message, the more questions required).
Shannon entropy is expressed as:
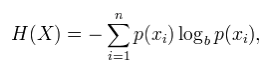 Where p(xi) is the probability of the xi sequence being in the message contents.
Where p(xi) is the probability of the xi sequence being in the message contents.
After analyzing a number of benign versus malicious websites, I found that the vast majority of benign sites had an entropy score between 5 and 6. For example,
.nobr br { display: none }
| Site | URL | Entropy Score |
|---|---|---|
| Google Search Results Page | http://www.google.com/search?q=test | 5.59684041594171 |
| CNN Home Page | http://www.cnn.com/ | 5.38281304867348 |
| YouTube Video Page | http://www.youtube.com/watch?v=YjZR1Rjj_p0 | 5.64757689191574 |
| Zscaler Blog | http://research.zscaler.com/ | 5.1860122562664 |
| Slashdot | http://slashdot.org/ | 5.24109568818941 |
| http://www.facebook.com/ | 5.44626483954319 | |
| Yahoo | http://www.yahoo.com/ | 5.66647432819298 |
| http://twitter.com/ | 5.07852673859431 | |
| Bing | http://www.bing.com/ | 5.70730460609158 |
| Weather | http://www.weather.com/ | 5.46749072998571 |
The above 10 pages had an average entropy score of: 5.44203995.
I pulled a number of malicious pages from MDL, MalwareURL, BLADE, and Zscaler's block logs. There was a larger diversity of entropy scoring, but what I noticed were a lot of results that scored outside of the 5-6 range that was popular for the benign sites. For example,
.nobr br { display: none }
| Site | URL | Entropy Score |
|---|---|---|
| Pheonix Exploit Kit | hxxp://cupidplaces.com/des/index.php | 6.07314762971744 |
| Eleonore Exploit Kit 1.3.2 | hxxp://godaddynon.com/31337/frv/index.php | 3.42515527587734 |
| Eleonore Exploit Kit 1.4 | hxxp://russian-post.net/otop/index.php | 4.35195257602932 |
| Pheonix Exploit Kit | hxxp://grinchalina5.com/pek/ | 5.41711832747246 |
| Injected obfuscated JS | hxxp://123celebritygossip.com/top-celebrity-biographies | 5.16329257317279 |
| YES Exploit Kit 3.0 | hxxp://img127.imageshack.uz/start.php | 6.07918073457686 |
| Exploit | hxxp://www.hao123.com.wwvv.us/images/css/jg.htm | 2.6484961921375 |
| NeoSploit | hxxp://sun.akkei.com/cgi-bin/engine.aspx | 5.36941875592612 |
| IE Exploit CVE-2010-0249 | hxxp://www.12388.info:778/ie.html | 4.71645042977322 |
| Fragus Exploit Kit | hxxp://79.39.52.17:555/counter/show.php | 3.35759918809499 |
Seven out of the above sample 10 malicious URLs fell outside the entropy range for the benign sites. The benign websites generally contained English content. The English alphabet has more entropy (upper/lower 26 letters, numbers, punctuation) than content that is made up of mostly Hex or encoded bytes (e.g., 0-9A-F). This is visible within the hao123.com exploit page, that has a very low entropy score. Some exploit kits used a larger and "more random" pool of characters in their encodings, variable names, etc. - these sites resulted in higher entropy scores.
JavaScript "Density" Scoring
Exploit kits and exploit pages frequently store large blocks of encoded content into variables that are then processed by the script to result in the exploit, shellcode, redirect, or other content. These large blocks of content make the JS for these pages more "dense" than JS found in typical websites. By calculating the average character sequence size I am able to apply a numerical "density" score to the script content. There is one problem with just separating character sequences by whitespace- a lot of JS has whitespace removed to save bandwidth (this is called JS minification), thus I also separate character sequences by a handful of JS characters, such as =;(){}.
Applying density scoring on the same malicious versus benign sites above resulted in the benign sites having an average density score of 13.6808922 while the malicious sites had an average of 42.3847881. Needless to say, there was a large disparity in the JS density between the malicious and benign sites that I tested.
Conclusions
Deobfuscating all JS within webpages as they fly across the wire is not very scalable. However, some techniques can be used to identify risky, or potentially malicious, obfuscated JS in realtime. This provides a smaller subset of JS to further analyze inline or block based upon thresholding. Preliminary results of some techniques, such as entropy and density scoring have produced some promising results. By releasing these results to the community, I hope to encourage others to conduct analysis and share their work/results for scalable solutions for inline JS analysis besides simple signatures. Below are some screenshots of an internal proof-of-concept that I built using the previously mentioned checks.
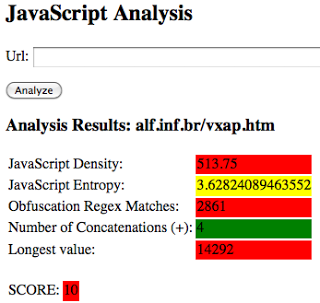
Exploit site example:
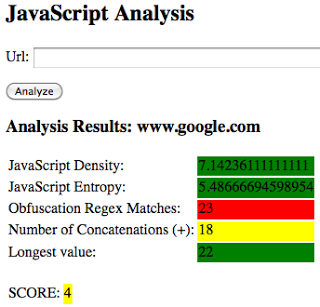
Benign site example: