
This post also appeared on LinkedIn.
The Zscaler Zero Trust Exchange, the cloud platform that power all Zscaler services, secures more than 150 billion transactions per day, protecting thousands of customers from cyberattacks and data loss. The Zscaler platforn is the world's largest inline security cloud, and the sheer volume of data it processes is astronomical to comprehend: Every second, another 1.6M transactions move securely through the platform. And in that one second, it blocks up to two thousand new threats.
The Zscaler Zero Trust Exchange produces mountains of data. For a relative sense of that scale, here are some comparable stats from other cloud platforms:
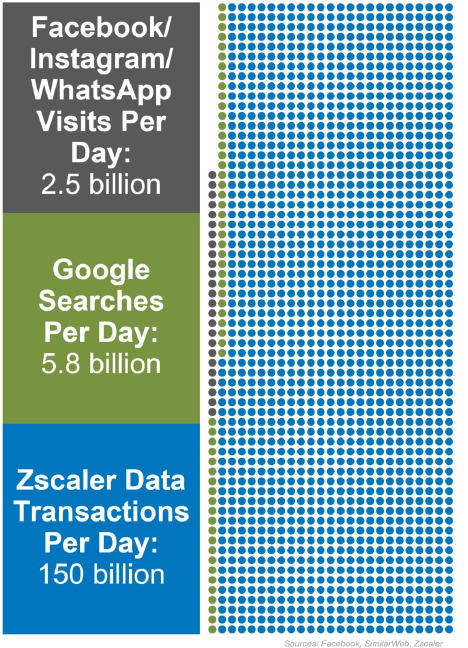
Figure 1. Comparing Zscaler data traffic to other cloud platforms. Each dot represents 100 million data points. (Sources: Facebook, Google, Zscaler.)
Finding meaning in all of that data is the shared responsibility of Zscaler’s engineering, research, and machine learning (ML) teams. I have the privilege to lead the ML group: We're tasked with staying ahead of advanced threats, and identifying and blocking threats before they become measurable risks. We comb through the mountains of Zscaler cloud data to identify threat patterns and block those advanced (and often previously unknown) advanced threats without signatures or human interaction.
The ML team’s work extends beyond protecting Zscaler customers' data traffic. The ML group collaborates with Zscaler big data, cloud reliability, TAM, and support teams to explore how to make the worldwide cloud operations smoother, using ML to craft actionable operational strategies based on our own operational data.
We work closely with Zscaler's operations and reliability teams: They employ a diverse set of tools and automation processes to maintain and monitor the Zscaler Zero Trust Exchange's highly scalable cloud infrastructure. Monitoring such a massively large-scale cloud isn't a trivial exercise without challenges. For example, the Zscaler cloud infrastructure must interact with some external networks. Often, performance or reliability issues—say, those related to an ISP problem—occur before data reaches the Zscaler cloud. And there's also the challenge of interpreting a massive volume of metrics: AIOps can help find higher-level patterns.
As part of our ongoing analysis, the ML team examines numerous metrics, including (but not limited to) volume, latency, traffic destination/direction. We leverage multiple ML models to find meaning in the performance data.
Anomaly detection for each metric can give us a single "dot” of alert, an individual data point that itself can be "noisy" and unclear. But the more anomaly-detection dots from other metrics we collect, the more vivid the picture we can illustrate: Our AI models correlate and (literally) connect the dots to draw the signal out of the noise.
We recently introduced new AIOps ML models and quickly discovered how effective they could be when put into practice. In January, a Zscaler customer's tunnels "flipped" at one of our data centers in Hong Kong. There was no impact on customer performance since that customer had followed Zscaler configuration best practices and established redundant tunnels. But the problem could have reflected a more significant issue.
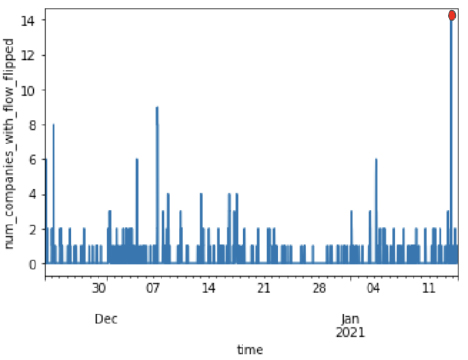
Figure 2. ZTE “flow” flipping analysis.
Figure 2 above shows the number of companies with flipping “flows.” The “flow” is a conceptual concept: Like a tunnel, but more granular than the standard GRE/IPsec tunnel. Picking up that spike is not as simple as it might look on the surface: assessing the flow requires interpreting a massive amount of data. Where do we draw the line to set a threshold alert? The top 1 spike? Top 10? Top 20? How should we balance the high detection rate vs. high accuracy? And how do we establish a threshold for a specific data center? Are there other metrics we should leverage together? Answering these questions requires statistical and ML baselining and modeling. Anyway, our AIOps ML testing model instantly picked up the real-world alert, enabling us to isolate and address the problem immediately.
The real problem we saw in the Hong Kong data center was occurring upstream of Zscaler, and was resolved after communication with the "mid-stream" ISP. Even without the AIOps model, Zscaler operations folks have discovered the problem, but the name of the game is the turnaround. Had our model been officially live at the time, we would have discovered (and then resolved) the issue even faster.
In this example, we were able to identify then resolve a problem at a customer's ISP before it impacted performance. We did it by finding a signal in the massive amount of data/metrics the Zscaler Ops team produces and by leveraging the domain expertise we have within the company.
Here at Zscaler, we are only just beginning our journey to apply AI and ML to impact customer cloud transformations. The future of AIOps—especially at Zscaler— is exciting and enables us to serve customers better and faster.




